 En
EnПередача данных между клиентом и сервером
KDV, www.ibase.ru, 03.02.2004, последнее обновление – 28.08.2007.
Для создания производительных приложений недостаточно научиться работать с клиентскими компонентами и SQL. Нужно еще понимать процессы, происходящие между клиентом и сервером при выполнении запросов.
Давайте рассмотрим взаимодействие на конкретном примере. В качестве клиента у нас выступает приложение и gds32.dll (fbclient.dll), поскольку все высокоуровневые вызовы компонент доступа к БД все равно превращаются в вызовы gds32.dll). Тип соединения (локальный, сетевой tcp или netbeui) не имеет значения.
Также опускаем все подробности по установке соединения и вызовам всяческих сервисных или информационных функций. Основная деятельность между клиентом и сервером – это обработка запросов SQL. На картинке изображена последовательность действий между клиентом и сервером при выполнении любого запроса. Пусть это будет
SELECT * FROM TEST
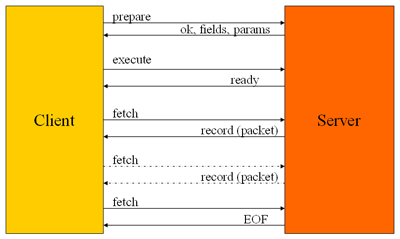
- Независимо от того, один вызов клиентской библиотеки выполняет запрос, или несколько, gds32.dll всегда начинает с Prepare. Prepare означает отправку запроса на сервер. При этом сервер
- проверяет синтаксическую корректность запроса
- проверяет наличие всех объектов, указанных в запросе, и права доступа к ним.
- формирует список возвращаемых столбцов и параметров (если таковые есть)
- передает клиенту результат prepare (ok, error), и списки столбцов и параметров (если есть)
после выполнения prepare от сервера можно получить план запроса – для примера см. код IBX.
- Раз запрос корректен, и вся информация для получения данных, возвращаемых запросом, получена от сервера, запрос можно выполнить. Вызывается Execute. Собственно, только в этот момент сервер начинает выполнять запрос.
На данном этапе, пока запрос не выполнится целиком, клиент не получит никакого сообщения. Под "выполнением" запроса означает готовность сервера к выдаче первой записи, возвращаемой запросом, или успешного/неуспешного выполнения запроса (например выполнение операторов ddl или процедур, не возвращающих результат, а также update, insert, delete).
Время выполнения запроса зависит от метода его обработки на сервере. Если это прямое считывание данных с диска (в натуральном порядке или по индексу), то ответ сервера на Execute придет быстро. Если это группировка или сортировка без использования индекса, то чем больше обрабатывается данных, тем дольше будет выполняться запрос.
Время выполнения запроса зависит от метода его обработки на сервере. Если это прямое считывание данных с диска (в натуральном порядке или по индексу), то ответ сервера на Execute придет быстро. Если это группировка или сортировка без использования индекса, то чем больше обрабатывается данных, тем дольше будет выполняться запрос.
- Запрос выполнен, и теперь клиент может начать получать записи (если они есть). Для этого клиент вызывает функцию Fetch. С точки зрения клиента (и приложения) Fetch – это получение одной записи. Но сервер всегда (кроме select for update) передает клиенту целый пакет записей. Поэтому первый Fetch приводит к получению пакета записей, а очередные Fetch – к выборке из полученного пакета (фактически буфера) до тех пор, пока записи в пакете не кончатся.
- Если в момент очередного Fetch клиент вместо данных записи получает EOF (End Of File), то значит на сервере данные кончились, и запрос можно закрыть.
В целом, не слишком сложная процедура. Но здесь есть два основных следствия:
- С момента выдачи серверу Execute до получения от сервера ответа (о готовности выдавать результат) клиент как бы "повисает", а сервер продолжает выполнять запрос "до упора". Если в этот момент принудительно "снять" клиентское приложение, сервер все равно проверит существование клиентского соединения только когда закончит выполнять запрос, т. е. соберется передавать результат клиенту. Существуют только две версии серверов, в которых запрос в этот момент можно отменить:
- IB 6.5, при помощи вызова IB API (в отдельном thread). Подробнее обратитесь к APIGuide.pdf от IB 6.5/7.0
- IB 7.x, при помощи временных системных таблиц (в отдельном коннекте). Подробнее см. OpGuide.pdf от IB 7.x
- На пути данных от сервера к клиенту может возникнуть тройная буферизация:
- данные запросов, сортируемые на диске, формируются в момент Execute и удерживаются сервером до тех пор, пока клиент не выберет последнюю запись. Т. е. это своеобразный "кэш запроса на сервере", причем кэш, индивидуальный для каждого запроса, содержащего в плане слово SORT.
- Клиент, запрашивая данные "поштучно", все равно получает от сервера "пакеты записей", т. е. буфер присутствует в gds32.dll
- Клиентские компоненты (BDE, FIBPlus, IBX...) так или иначе тоже буферизируют принимаемые данные. Особенно это относится к компонентам dbExpress, где обеспечить навигацию по записям можно только буферизировав их (целиком все записи) при помощи ClientDataSet.
Не буферизируют записи такие компоненты, как IBX.IBSQL и FIBPlus.pFIBQuery.
Из этих следствий, соответственно, можно сделать выводы:
- Сортировка большого количества записей приводит к длительному выполнению запроса на сервере (методы ускорения этого есть во всех последних версиях IB, FB и YA) и к неспособности клиента в это время выполнять другие действия (в этом коннекте. О параллельной работе в разных коннектах см. FAQ).
- Многочисленная буферизация приводит к тому, что данные становятся "неактуальными" задолго до того, как клиент их начнет просматривать. Собственно, здесь нет никаких проблем с точки зрения целостности данных в транзакции.