 En
EnИспользование неявных и явных JOIN в InterBase и Firebird
KDV, 23.04.2005, последнее обновление – 17.07.2005, 13.10.2005.
на текущий момент статья не завершена
Модель примеров
В качестве модели БД для описания примеров используется примитивная БД, учитывающая клиентов, товары, заказы и заказываемые товары. Ваша предметная область может быть совершенно другой, однако данная модель является максимально простой и понятной. Знания, полученные из этой статьи, вы сможете с легкостью применить к своей БД.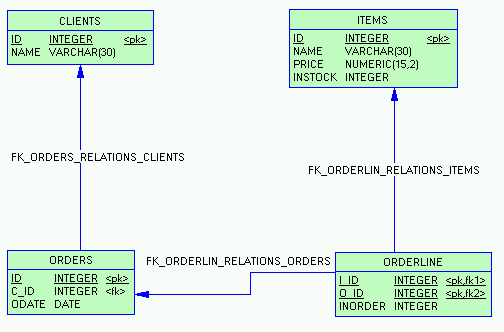
Большинство последующих запросов будут приведены на примере этой модели. Модель в PowerDesigner 11, скрипт для создания БД и готовая БД (с примером данных) в формате ODS 10 (Firebird 1.5) находится здесь.
Модель достаточно проста – клиенты, которые делают заказы, заказы товаров отслеживаются в orderline.
Примечание. Пожалуйста, не предъявляйте претензии к тому, что в clients не указан телефон и адрес клиента, что в items не указана единица измерения товара, что столбец inorder имеет тип integer, и т. п. Данная модель является всего лишь примером, и разумеется, для конкретного случая должна учитывать все особенности вашей прикладной области.
Примечание. Столбцам идентификаторов и названий не случайно даны абстрактные имена id и name. С одной стороны, разработчики зачастую так и делают. Другие же предпочитают даже идентификаторы именовать с учетом принадлежности таблице. Например, C_ID или CLIENT_ID. В данном примере ID и NAME использованы намеренно, для того чтобы показать необходимость использования алиасов таблиц, и возможность использования алиасов столбцов – см. далее пример полного объединения 4-х таблиц.
Неявный join
Неявные объединения таблиц – это синтаксис SQL89. На тот момент в стандарте SQL явные join еще отсутствовали. Конструкция достаточно проста:select ... from a, b
where a.id = b.a_id
where a.id = b.a_id
Допустим, a – это справочник пользователей, а b – это таблица заказов. В этом случае мы объединяем таблицы пользователей и заказов по столбцу первичного ключа таблицы a и столбцу связи таблицы b.
Дополнительные условия в where – это дополнительная "фильтрация" результатов запроса. Например, нам надо выбрать всех клиентов, которые делали заказы в определенный период:
select c.id, c.name
from clients c, orders o
where c.id = o.c_id and o.odate between '01.01.2005' and '01.02.2005'
ID NAME
3 ИП Сидоров И.И.
1 AllInOne
1 AllInOne
from clients c, orders o
where c.id = o.c_id and o.odate between '01.01.2005' and '01.02.2005'
ID NAME
3 ИП Сидоров И.И.
1 AllInOne
1 AllInOne
В данном случае c.id = o.c_id является условием объединения клиентов и заказов, а o.odate between ... – условием "фильтрации" результата по дате заказов.
Если мы забудем указать условие объединения таблиц, то результатом будет декартово произведение таблиц. То есть, итоговое количество записей будет равно произведению числа записей объединяемых таблиц
select ... from a, b
Такой тип объединения редко нужен, поэтому в практическом применении его можно считать ошибочным. Часто это происходит, когда объединяется много таблиц, и разработчик случайно не указал объединение одной из таблиц с остальными.
Оптимизатор при неявных объединениях использует информацию статистики по существующим индексам, поэтому для правильной оптимизации неявных join требуется регулярно обновлять статистику по всем индексам БД (set statistics index <indexname>. В IBExpert это можно сделать в меню алиаса БД – recompute index selectivity).
В качестве последнего примера неявных join – полное объединение всех четырех таблиц:
select c.name, o.id orderid, o.odate, i.name, i.price,
s.inorder, (i.price * s.inorder) itemsum
from clients c, orders o, items i, orderline s
where c.id = o.c_id and
where c.id = o.c_id and
o.id = s.o_id and
i.id = s.i_id
i.id = s.i_id
| NAME | ORDERID | ODATE | NAME1 | PRICE | INORDER | ITEMSUM |
| ИП Сидоров И.И. | 1 | 22.01.2005 | Пиво Балтика N 7 | 20 | 10 | 200 |
| AllInOne | 3 | 24.01.2005 | Пиво Балтика N 7 | 20 | 5 | 100 |
| AllInOne | 2 | 23.01.2005 | Сигареты Дукат | 9 | 10 | 90 |
| ИП Сидоров И.И. | 1 | 22.01.2005 | Сыр Пошехонский | 120 | 2 | 240 |
| AllInOne | 2 | 23.01.2005 | Сыр Пошехонский | 120 | 4 | 480 |
| AllInOne | 2 | 23.01.2005 | Масло Крестьянское | 18 | 3 | 54 |
В результате получаем "денормализованный" вид – какой клиент, в каком заказе, когда, какой товар и в каком количестве и на какую сумму приобрел (почему данные идут в "беспорядке"? Потому что порядок записей гарантируется только при указании order by).
Примечание. Обратите внимание на:
а) алиасы таблиц. Без использования алиасов таблиц все версии InterBase (кроме Firebird начиная с 1.0) могут выдать непредсказуемый результат, то есть, перепутать местами столбцы NAME из таблицы товаров и таблицы клиентов. Алиасы позволяют не только избежать этого, но и повышают "переносимость" запроса, а также облегчают понимание, из какой таблицы выбирается какой столбец (даже если в выборке нет одинаковых имен столбцов). В Firebird 2.0 не допускается смешивание алиасов и имен таблиц, не рекомендуется это делать и для других версий InterBase и Firebird.
б) имена столбцов NAME и NAME1. Если в выборке 2 столбца с одинаковым именем, то сервер автоматически нумерует повторяющиеся. Чтобы этого не происходило, нужно использовать алиасы имен столбцов. Например,
select c.name client_name, ..., i.name item_name ...
То же самое можно сказать и о вычисляемых полях, столбцах агрегатов и т. п. Более того, InterBase/Firebird в разных версиях могут именовать такие столбцы по разному.
а) алиасы таблиц. Без использования алиасов таблиц все версии InterBase (кроме Firebird начиная с 1.0) могут выдать непредсказуемый результат, то есть, перепутать местами столбцы NAME из таблицы товаров и таблицы клиентов. Алиасы позволяют не только избежать этого, но и повышают "переносимость" запроса, а также облегчают понимание, из какой таблицы выбирается какой столбец (даже если в выборке нет одинаковых имен столбцов). В Firebird 2.0 не допускается смешивание алиасов и имен таблиц, не рекомендуется это делать и для других версий InterBase и Firebird.
б) имена столбцов NAME и NAME1. Если в выборке 2 столбца с одинаковым именем, то сервер автоматически нумерует повторяющиеся. Чтобы этого не происходило, нужно использовать алиасы имен столбцов. Например,
select c.name client_name, ..., i.name item_name ...
То же самое можно сказать и о вычисляемых полях, столбцах агрегатов и т. п. Более того, InterBase/Firebird в разных версиях могут именовать такие столбцы по разному.
Другие варианты неявных объединений
Перечисленное дальше является не совсем "объединением", но позволяет получить аналогичный (зачастую) результат. Например, требуется найти клиентов, которые делали заказы (вообще). Начинающие разработчики обычно пишут следующий запрос:select c.name
from clients c
where c.id in (select o.c_id from orders o)
NAME
AllInOne
ИП Сидоров И.И.
PLAN (O INDEX (FK_ORDERS_RELATIONS_CLIENTS))
PLAN (C NATURAL)
from clients c
where c.id in (select o.c_id from orders o)
NAME
AllInOne
ИП Сидоров И.И.
PLAN (O INDEX (FK_ORDERS_RELATIONS_CLIENTS))
PLAN (C NATURAL)
Собственно, если стоит именно такая задача – получить уникальные наименования клиентов, которые делали заказы, без повторов, то этот запрос на 100% правилен. То же самое можно получить запросом
select distinct c.name
from clients c, orders o
where c.id = o.c_id
который теоретически хуже тем, что для выполненного join производится сортировка результата с выбрасыванием повторяющихся имен:
from clients c, orders o
where c.id = o.c_id
PLAN SORT (JOIN (O NATURAL,C INDEX (PK_CLIENTS)))
С точки зрения логики запроса where c.id in (select ... вроде бы все нормально, но оптимизатор (во всех версиях InterBase, Firebird, Yaffil, по крайней мере до Firebird 2.0) считает данный вариант эквивалентом не объединения, а подзапроса с exists
select c.name
from clients c
where exists (select o.c_id from orders o where c.id = o.c_id)
NAME
AllInOne
ИП Сидоров И.И.
from clients c
where exists (select o.c_id from orders o where c.id = o.c_id)
NAME
AllInOne
ИП Сидоров И.И.
Именно поэтому таблица clients перебирается целиком, и для каждой ее записи производится выполнение вложенного запроса к orders, т. к. вложенный запрос коррелирован с внешним по c.id = o.c_id.
Явные join
Синтаксис явных объединений появился в SQL92 (поэтому в той книге М. Грабера, которая находится в интернете, нет упоминания о join – она вышла до 1992 года. Зато полное описание явных join есть в более новом издании этой же книги). InterBase поддерживает явные join в стандартном синтаксисе с версии 4.0. Вот поддерживаемый синтаксис join из langref.pdf:<joined_table> = tableref join_type JOIN tableref
ON search_condition | (joined_table)
<join_type> = [INNER] JOIN | {LEFT | RIGHT | FULL } [OUTER]}
Это означает, что INNER JOIN = JOIN, а LEFT/RIGHT OUTER JOIN = LEFT/RIGHT JOIN, то есть слова INNER и OUTER являются необязательными.При этом, в отличие от неявного join, условие объединения таблиц (on) и условия "фильтрации" where разделены (см. дальше).
Явный join – эквивалент неявного объединения
select ... from
a join b on a.id = b.a_id
a join b on a.id = b.a_id
Если в неявном join условие объединения указывается как "фильтрация" результата в where, то в данном случае условие объединения указывается в on.
Отличие между On и Where
Как только в запросе указан явный join, сервер объединяет таблицы по указанию связи столбцов в ON, а условие where использует как условие "фильтрации" результата данного объединения. То есть, where выполнятеся как бы над результатом объединения.Внимание! На самом деле, конечно, сервер делает поиск по where одновременно с объединением (за исключением is null и is distinct (в FB2). Здесь where упомянут как "фильтрация результата" только для того, чтобы было понятно отличие между результатами выборки в последующих примерах.
Допустим, мы хотим выбрать заказы клиентов, название которых начинается с буквы 'А'. Тогда мы должны написать так:
select c.id clientid, c.name, o.id orderid, o.odate
from clients c join orders o
on c.id = o.c_id and c.name starting with 'A'
CLIENTID NAME ORDERID ODATE
1 AllInOne 2 23.01.2005
1 AllInOne 3 24.01.2005
from clients c join orders o
on c.id = o.c_id and c.name starting with 'A'
CLIENTID NAME ORDERID ODATE
1 AllInOne 2 23.01.2005
1 AllInOne 3 24.01.2005
То есть, условие отбора клиентов по имени, начинающемуся с A, включено в условие объединения.
Можно, конечно, указать данное условие и в where
select c.id clientid, c.name, o.id orderid, o.odate
from clients c join orders o on c.id = o.c_id
where c.name starting with 'A'
CLIENTID NAME ORDERID ODATE
1 AllInOne 2 23.01.2005
1 AllInOne 3 24.01.2005
но в этом случае для понимания разницы между WHERE и ON в явных объединениях запрос надо рассматривать так, как будто сервер сначала выполненит объединение, и только затем отбросит лишние записи, где c.name не начинается с буквы 'A' (в конкретном случае планы двух последних запросов идентичны). Далее будут показаны дополнительные примеры использования on с where.
from clients c join orders o on c.id = o.c_id
where c.name starting with 'A'
CLIENTID NAME ORDERID ODATE
1 AllInOne 2 23.01.2005
1 AllInOne 3 24.01.2005
Смешивание явных и неявных join
При использовании явных JOIN крайне не рекомендуется смешивать данный синтаксис с неявными JOIN. Например,select ...
from a, b join c on ...
from a, b join c on ...
Здесь, даже если условие объединения для a и b указано в where, сервер выполнит этот запрос как объединение (см. выше) таблиц b и c, и затем с результатом объединения выполнит декартово произведение с таблицей a.
То есть, на самом деле написанное выше интерпретируется как
select ...
from (b join c) cross join a
from (b join c) cross join a
Примечание. Cross join – эквивалент неявного объединения без where, то есть декартова произведения. Явный синтаксис cross join поддерживается в Firebird 2.0.
Left/Right Join
Левое и правое объединения называются "внешними". В случае внешнего объединения одна из объединяемых таблиц (если left, то "слева", если right, то "справа") выбирается целиком, а вторая – только по условию объединения. Если возникают сомнения, где у сервера "право и лево", то вот пример:таблица_слева left join таблица_справа on ...
Здесь таблица_слева будет выбрана целиком, а из таблицы_справа будут выбраны только те записи, которые соответствуют записям таблицы_слева.
Такие запросы необходимы, например, для случаев, когда из справочной таблицы нужно взять все записи, а из оперативных – только те, которые соответствуют справочной.
Допустим, нам нужно посмотреть абсолютно всех клиентов, и какие они делали заказы (если делали вообще). Предыдущие примеры с неявным или явным join позволяли нам посмотреть только тех, клиентов, которые хотя бы один раз делали заказы.
select c.id clientid, c.name, o.id orderid, o.odate
from
clients c left join orders o on c.id = o.c_id
from
clients c left join orders o on c.id = o.c_id
CLIENTID NAME ORDERID ODATE
1 AllInOne 2 23.01.2005
1 AllInOne 3 24.01.2005
2 ООО "АБВ" <null> <null>
3 ИП Сидоров И.И. 1 22.01.2005
Здесь мы видим, что оказывается, клиент с номером 2 не делал заказов вообще. То есть, столбцы o.id и o.odate содержат null (в примерах null помечен красным не потому, что он относится к таблице_слева, а для того, чтобы вы просто обратили на него внимание. Здесь и дальше null содержат столбцы той таблицы, которая в явном join объединяется с противоположной стороны по отношению к таблице, выбираемой целиком – то есть столбцы таблицы_справа). Сервер выбрал данные как мы и просили – все записи из clients, и соответствующие им записи из orders. Для записи 2 в clients соответствующих в orders не нашлось, поэтому столбцы orders содержат null.1 AllInOne 2 23.01.2005
1 AllInOne 3 24.01.2005
2 ООО "АБВ" <null> <null>
3 ИП Сидоров И.И. 1 22.01.2005
Теперь вспомните, что говорилось выше об отличиях ON и WHERE. Допустим, мы хотим получить всех клиентов, но только те заказы, которые делались за определенный период. Вставим условие в объединение по ON.
select c.id clientid, c.name, o.id orderid, o.odate
from
clients c left join orders o on c.id = o.c_id
and o.odate between '01.01.2005' and '23.01.2005'
CLIENTID NAME ORDERID ODATE
1 AllInOne 2 23.01.2005
2 ООО "АБВ" <null> <null>
3 ИП Сидоров И.И. 1 22.01.2005
from
clients c left join orders o on c.id = o.c_id
and o.odate between '01.01.2005' and '23.01.2005'
CLIENTID NAME ORDERID ODATE
1 AllInOne 2 23.01.2005
2 ООО "АБВ" <null> <null>
3 ИП Сидоров И.И. 1 22.01.2005
Все нормально, в списке мы получили и запись клиента с кодом 2. Поскольку задан интервал для заказов, мы можем утверждать что клиент 2 не делал заказов в этом интервале дат (хотя конкретно этот клиент не делал заказов вообще, что видно из предыдущего запроса). Но если мы добавим условие фильтрации по привычке, как с неявными join, то есть в where
select c.id clientid, c.name, o.id orderid, o.odate
from
clients c left join orders o on c.id = o.c_id
where o.odate between '01.01.2005' and '23.01.2005'
CLIENTID NAME ORDERID ODATE
1 AllInOne 2 23.01.2005
3 ИП Сидоров И.И. 1 22.01.2005
то разумеется, условие будет "применено к результату объединения", и мы не увидим отсутствия заказов для клиента 2. То есть, мы "свели" этот запрос к обычному inner join, и для получения правильного результата (с отсутствующими заказами для клиентов) необходимо в where добавить условие o.odate is null
from
clients c left join orders o on c.id = o.c_id
where o.odate between '01.01.2005' and '23.01.2005'
CLIENTID NAME ORDERID ODATE
1 AllInOne 2 23.01.2005
3 ИП Сидоров И.И. 1 22.01.2005
select c.id clientid, c.name, o.id orderid, o.odate
from
clients c left join orders o on c.id = o.c_id
where o.odate between '01.01.2005' and '23.01.2005' or o.odate is null
CLIENTID NAME ORDERID ODATE
1 AllInOne 2 23.01.2005
2 ООО "АБВ" <null> <null>
3 ИП Сидоров И.И. 1 22.01.2005
from
clients c left join orders o on c.id = o.c_id
where o.odate between '01.01.2005' and '23.01.2005' or o.odate is null
CLIENTID NAME ORDERID ODATE
1 AllInOne 2 23.01.2005
2 ООО "АБВ" <null> <null>
3 ИП Сидоров И.И. 1 22.01.2005
Понятно, что данное условие (o.odate is null) здесь совершенно лишнее, то есть условие объединения-отбора по дате было некорректно перенесено в условие фильтрации-where.
Кстати, как раз условием фильтрации where очень удобно выбирать только тех клиентов, которые не делали заказы (или те товары, которые не были заказаны, и т. п.):
select c.id clientid, c.name, o.id orderid
from
clients c left join orders o on c.id = o.c_id
where o.id is null
CLIENTID NAME ORDERID
2 ООО "АБВ" <null>
from
clients c left join orders o on c.id = o.c_id
where o.id is null
CLIENTID NAME ORDERID
2 ООО "АБВ" <null>
Условием where o.id is null мы "отсекаем" все записи orders, соотвествующие записям clients. Так и есть, эта фирма не делала ни одного заказа (тот же самый результат можно получить при помощи вложенного запроса по not exists, только зачастую с худшей производительностью. Попробуйте на вашей базе оба варианта).
Столбцы связи с null
Попытка имитировать left join при помощи объединения inner join с условием or o.odate is null приведет к совершенно другому результатуselect c.id clientid, c.name, o.id orderid, o.odate
from
clients c join orders o on c.id = o.c_id or o.c_id is null
from
clients c join orders o on c.id = o.c_id or o.c_id is null
CLIENTID NAME ORDERID ODATE
1 AllInOne 2 23.01.2005
1 AllInOne 3 24.01.2005
1 AllInOne 4 01.02.2005
2 ООО "АБВ" 4 01.02.2005
3 ИП Сидоров И.И. 1 22.01.2005
3 ИП Сидоров И.И. 4 01.02.2005
1 AllInOne 2 23.01.2005
1 AllInOne 3 24.01.2005
1 AllInOne 4 01.02.2005
2 ООО "АБВ" 4 01.02.2005
3 ИП Сидоров И.И. 1 22.01.2005
3 ИП Сидоров И.И. 4 01.02.2005
Результат выглядит достаточно странно, не так ли? Заказ N 4 – якобы его сделали все 3 клиента одновременно. В чем дело?
Если поле связи со справочной таблицей не указано как not null, то Foreign Key допускает null, то есть даже в нашем примере можно создать заказ, сделанный неизвестно каким клиентом. К примеру, на момент формирования заказа клиент хочет остаться "инкогнито", и если стоимость заказа его устроит – только тогда он его и оплатит (другие ситуации – на ваш вкус).
В этом случае при объединении таблицы клиентов и заказов, для просмотра вообще всех заказов, нам пришлось бы вместо обычного объединения (неявного или inner join) делать внешнее объединение для orders. Например,
select c.id clientid, c.name, o.id orderid, o.odate
from
clients c right join orders o on c.id = o.c_id
from
clients c right join orders o on c.id = o.c_id
CLIENTID NAME ORDERID ODATE
3 ИП Сидоров И.И. 1 22.01.2005
1 AllInOne 2 23.01.2005
1 AllInOne 3 24.01.2005
<null> <null> 4 01.02.2005
3 ИП Сидоров И.И. 1 22.01.2005
1 AllInOne 2 23.01.2005
1 AllInOne 3 24.01.2005
<null> <null> 4 01.02.2005
Здесь обнаруживается запись с заказом N 4, для которой нет известного клиента из clients. Обратите внимание, что ни один предыдущий запрос не выводил эту запись (просто потому, что у нас везде использовалось объединение по c.id = o.c_id, а в этом случае записи с null игнорируются как для c.id так и для o.c_id).
Конечно, можно было бы or o.C_ID is null и в явный join дописать
select c.id clientid, c.name, o.id orderid, o.odate
from
clients c join orders o on c.id = o.c_id or o.C_ID is null
или написать неявный join так
from
clients c join orders o on c.id = o.c_id or o.C_ID is null
select c.id clientid, c.name, o.id orderid, o.odate
from
clients c, orders o
where c.id = o.c_id or o.C_ID is null
from
clients c, orders o
where c.id = o.c_id or o.C_ID is null
Оба эти запроса выдадут одинаковый результат (см. результат первого запроса этого раздела). При этом вместо записи с заказом 4 и null в информации о клиенте получим 3 раза (по числу записей в clients) указание на то, что разные клиенты делали этот заказ N 4. Почему?
Вспомните упомянутое выше "перемножение" таблиц. Давайте уберем из любого из двух последних запросов условие c.id = o.c_id и посмотрим на результат. Действительно,
select c.id clientid, c.name, o.id orderid, o.odate
from
clients c, orders o
where o.C_ID is null
CLIENTID NAME ORDERID ODATE
1 AllInOne 4 01.02.2005
2 ООО "АБВ" 4 01.02.2005
3 ИП Сидоров И.И. 4 01.02.2005
from
clients c, orders o
where o.C_ID is null
CLIENTID NAME ORDERID ODATE
1 AllInOne 4 01.02.2005
2 ООО "АБВ" 4 01.02.2005
3 ИП Сидоров И.И. 4 01.02.2005
Почему, все-таки, это произошло? Потому что условие o.c_id is null не является условием объединения двух таблиц. Это всего лишь условие, ограничивающее записи в одной из таблиц. А указанное в качестве OR с c.id = o.c_id оно просто добавляет эти записи к объединению, выполненному по условию c.id = o.c_id. Чтобы убедиться в этом, добавим к списку выбираемых столбцов o.c_id
select c.id clientid, c.name, o.id orderid, o.odate, o.c_id
from
clients c join orders o on c.id = o.c_id or o.C_ID is null
CLIENTID NAME ORDERID ODATE C_ID
1 AllInOne 2 23.01.2005 1
1 AllInOne 3 24.01.2005 1
1 AllInOne 4 01.02.2005 <null>
2 ООО "АБВ" 4 01.02.2005 <null>
3 ИП Сидоров И.И. 1 22.01.2005 3
3 ИП Сидоров И.И. 4 01.02.2005 <null>
from
clients c join orders o on c.id = o.c_id or o.C_ID is null
CLIENTID NAME ORDERID ODATE C_ID
1 AllInOne 2 23.01.2005 1
1 AllInOne 3 24.01.2005 1
1 AllInOne 4 01.02.2005 <null>
2 ООО "АБВ" 4 01.02.2005 <null>
3 ИП Сидоров И.И. 1 22.01.2005 3
3 ИП Сидоров И.И. 4 01.02.2005 <null>
Так что, будьте внимательны с условиями join и where в подобных случаях.
Кстати, даже такие "монстры" РСУБД как К. Дж. Дейт не рекомендуют допускать null в столбце связи со справочником. Вместо null рекомендуется завести в справочнике запись с идентификатором 0 и названием "значение отсутствует" (или любым другим). В этом случае все вышеприведенные неявные и явные join вернут запись в orders для заказа 4 и соответственно, название клиента "отсутствует". При этом для поиска "неопознанных" заказов отпадает необходимость использования внешнего объединения.
- получить все связанные записи клиентов и заказов
- получить всех клиентов которые не делали заказы
- получить все заказы, сделанные неизвестными клиентами
select c.id clientid, c.name, o.id orderid, o.odate, o.c_id
from
clients c full join orders o on c.id = o.c_id
CLIENTID NAME ORDERID ODATE C_ID
3 ИП Сидоров И.И. 1 22.01.2005 3
1 AllInOne 2 23.01.2005 1
1 AllInOne 3 24.01.2005 1
<null> <null> 4 01.02.2005 <null>
2 ООО "АБВ" <null> <null> <null>
Как и в примерах предыдущего раздела, видно, что ООО "АБВ" не делало ни одного заказа, а заказ 4 сделан неизвестно каким клиентом. В том случае, когда с одной из сторон гарантированно нет отсутствующих записей (например, FK на клиентов в таблице заказов C_ID не допускает NULL), использовать FULL JOIN не имеет смысла. По производительности это плохой запрос, т.к. без дополнительных условий отбора оптимизатор генерирует план
from
clients c full join orders o on c.id = o.c_id
CLIENTID NAME ORDERID ODATE C_ID
3 ИП Сидоров И.И. 1 22.01.2005 3
1 AllInOne 2 23.01.2005 1
1 AllInOne 3 24.01.2005 1
<null> <null> 4 01.02.2005 <null>
2 ООО "АБВ" <null> <null> <null>
PLAN JOIN (O NATURAL,C NATURAL)
то есть, количество обращений к записям будет равно произведению числа таблиц в orders и clients.
select ... from
a left join b on a.id = b.a_id
select ... from
b right join a on a.id = b.a_id
a left join b on a.id = b.a_id
select ... from
b right join a on a.id = b.a_id
И, разумеется, вы уже убедились, что запросы a left join b и a right join b дадут разный результат.
В идеальном случае, когда нет заказов для неизвестных клиентов, и все клиенты делали хотя бы по одному заказу, результаты a left/right join b будут идентичными (нет "лишних" записей ни слева ни справа). Помните об этом, если в условие объединения добавляется условие, ограничивающее противоположную таблицу, например, по дате. В этом случае могут "появиться" клиенты, которые не делали заказов в конкретном интервале дат (или при других условиях).
Вообще все реляционные операции являются математическими операциями над множествами. Поэтому то, как сервер выполняет запрос, обусловлено не какими то достоинствами или недостатками оптимизатора, а тем, что для объединения двух множеств просто не существует других способов.
select c.name, o.odate, s.i_id itemid, s.inorder
from clients c, orders o, orderline s
where c.id = o.c_id and s.o_id = o.id
PLAN JOIN (S NATURAL,
from clients c, orders o, orderline s
where c.id = o.c_id and s.o_id = o.id
PLAN JOIN (S NATURAL,
O INDEX (PK_ORDERS),
C INDEX (PK_CLIENTS))
C INDEX (PK_CLIENTS))
Если тот же запрос переписать на явный join
select c.name, o.odate, s.i_id itemid, s.inorder
from
clients c join orders o on c.id = o.c_id
from
clients c join orders o on c.id = o.c_id
join orderline s on s.o_id = o.id
то план будет тем же самым:
PLAN JOIN (S NATURAL,
O INDEX (PK_ORDERS),
C INDEX (PK_CLIENTS))
Здесь мы можем видеть только то, что "планирование" неявных и явных inner join сервером выполняется одинаково. Но это совсем не так для outer join...C INDEX (PK_CLIENTS))
Продолжение следует...
Спасибо Константину Беляеву, Дмитрию Еманову, Александру Сурину за замечания по тексту статьи.