 En
EnДревовидные (иерархические) структуры данных в реляционных базах данных
Кузьменко Дмитрий, iBase.ru

Введение
Замечание. Документ был написан в 1997 г. С тех пор мало что изменилось в описываемой области.
Сегодня большинство хранилищ данных, как простых так и сложных, построены на основе реляционных баз данных. В них используются либо файл-серверные системы (dBase, Paradox, Clipper, FoxPro, Access), либо SQL-серверы (Oracle, Informix, Sybase, Borland InterBase, MS SQL и т. д.). Реляционные базы данных в большинстве случаев удовлетворяют требования какой-либо предметной области данных, но часты и случаи когда требуется представление и хранение данных в иерархическом виде. Варианты построения таких представлений в реляционной модели и будут рассмотрены в данной статье.Используемые инструменты
В качестве инструмента разработки клиентского приложения в данной статье применяется Delphi, а в качестве SQL-сервера – Borland InterBase SQL Server 4.x. На самом деле для теоретической части статьи это несущественно, а практическая часть содержит минимум специфики использования указанных инструментов.Таблицы-объекты
Для того, чтобы подойти к построению "деревьев", мы должны рассмотреть, что представляет собой реляционная таблица.
Рис. 1
Таблица имеет структуру, т. е. состоит из полей, описывающих характеристики некоего объекта, например, "Человек". Записи такой таблицы (можно назвать ее "Люди") представляют собой характеристики экземпляров объектов одного и того же типа. Идентификатор позволяет найти среди множества экземпляров один экземпляр требуемого типа.
Однотипные связанные объекты
Предположим что мы действительно хотим создать таблицу "Люди", в которой нужно отслеживать родственные связи типа родитель-потомок. Для простоты представим себе, что у потомков родитель может быть только один (например, "Родитель"):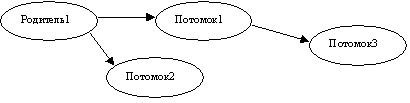
Рис. 2
Для того, чтобы хранить информацию о родителе экземпляра объекта, любой объект в таблице должен помимо идентификатора иметь атрибут "родитель". На рисунке видно, что все "Потомки" имеют родителя, кроме самого "Родитель1". Экземпляр "Родитель1" может в принципе вообще отсутствовать – можно принять что у потомков первого уровня всегда один и тот же родитель, поэтому хранить информацию о нем необязательно (в каких случаях это необходимо, мы рассмотрим дальше).
Читатель может заметить – а как же множественное наследование? А никак. В природе такового не существует – все объекты реального мира являются или цельными, или составными. Множественное наследование было создано только как методика проектирования классов, когда разработчик не обладает полной информацией о самих классах. Автор статьи считает, что множественное наследование только запутывает реализацию прикладной области. Например, в ряде книг приводится случай, когда объект "тесто" получается множественным наследованием объектов "вода" и "мука". На самом деле это не так – даже при диффузии отдельные материалы все равно остаются сами собой, т. е. в данном случае мы имеем совершенно новый объект "тесто", который имеет среди атрибутов указатели на два класса – "тесто" и "вода" (или список составляющих "тесто" классов, как угодно). Характеристики "теста" при этом зависят не только от состава "воды" и "муки", но и от их процентного соотношения. То же самое относится и к биологическому "рождению" – ребенок наследует свойства родителей, т. е. их наборы хромосом, и представляет собой типичный составной объект при отсутствии какого бы то ни было множественного наследования. Конечно, множественное наследование в редких случаях облегчает программирование, однако это не значит, что оно отражает суть реальных вещей, которые можно описать в программе.
Итак, структура нашей "родовитой" таблицы будет выглядеть следующим образом:

Рис. 3
Поле "Родитель" всегда ссылается на значение поля "Идентификатор". Здесь нас поджидает подводный камень – если бы мы решили, что "…ссылается на существующее значение поля…", и в соответствии с реляционными правилами объявили-бы связь конструкцией SQL "alter table … add constraint … foreign key", то попали-бы в замкнутый круг "курица и яйцо". Как создать экземпляр объекта если родителя нет? Действительно, может-ли существовать экземпляр объекта без указания родителя? Чтобы избавиться на начальном этапе хотя-бы от первого вопроса, нужно отказаться от декларации связи Родитель->Идентификатор на уровне сервера. Это снизит защищенность данных, но избавит нас от долгих раздумий в самом начале пути. На второй вопрос (может-ли существовать экземпляр без родителя) можно безболезненно ответить "нет", установив ограничение целостности для поля "Родитель" как "значение обязательно" (NOT NULL).
Поскольку мы отказались от создания FK, по полю "родитель" не будет автоматически построен индекс, который был бы нужен оптимизатору для ускорения запросов, выбирающих группы потомков для конкретного родителя. Не забудьте добавить такой индекс потом, вручную.
Давайте теперь посмотрим, как будет выглядеть таблица, заполненная экземплярами объектов с рисунка 2:
| Идентификатор | Родитель | Остальные атрибуты … |
|---|---|---|
| Родитель1 | ??? | |
| Потомок1 | Родитель1 | |
| Потомок2 | Родитель1 | |
| Потомок3 | Потомок1 |
Такую таблицу можно создать конструкцией SQL:
CREATE TABLE OBJECTS(
ID INTEGER NOT NULL,
PARENT INTEGER NOT NULL,
NAME VARCHAR(30),
constraint PK_OBJECTS primary key (ID))
ID INTEGER NOT NULL,
PARENT INTEGER NOT NULL,
NAME VARCHAR(30),
constraint PK_OBJECTS primary key (ID))
Пусть идентификаторы экземпляров объектов будут начинаться с номера 1. Тогда родителем экземпляра "Родитель1" можно принять значение 0 (корневой элемент). Фактически экземпляров с родителем = 0 может быть сколько угодно, и именно они будут представлять "корень" нашего дерева. Названия экземпляров пусть находятся в поле "NAME". Пронумеруем идентификаторы экземпляров объектов. В этом случае таблица будет иметь вид
| ID | PARENT | NAME |
|---|---|---|
| 1 | 0 | Родитель1 |
| 2 | 1 | Потомок1 |
| 3 | 1 | Потомок2 |
| 4 | 2 | Потомок3 |
SELECT * FROM OBJECTS
WHERE PARENT = 0
WHERE PARENT = 0
Ответ на этот запрос будет выглядеть так:
1 0 Родитель1
Теперь, для того чтобы получить всех потомков например экземпляра "Родитель1", нужно использовать его ID в том же самом запросе как идентификатор родителя:
SELECT * FROM OBJECTS
WHERE PARENT = 1
WHERE PARENT = 1
Ответ на этот запрос будет выглядеть так:
2 1 Потомок1
3 1 Потомок2
3 1 Потомок2
Таким образом получить список записей любого уровня можно одним и тем же запросом:
ВЫБРАТЬ ВСЕ_ПОЛЯ ИЗ ТАБЛИЦЫ
ГДЕ РОДИТЕЛЬ = ИДЕНТИФИКАТОР
ГДЕ РОДИТЕЛЬ = ИДЕНТИФИКАТОР
Представить такую информацию можно в виде "каталогов" и "файлов", например, как в Windows Explorer. Щелчок мыши по каталогу приводит к "проваливанию" на более глубокий уровень, и т. д.
Конечно, для того чтобы иметь возможность вернуться назад по дереву нужно в приложении хранить "список возврата", т. е. список элементов, по которым мы углубились внутрь, с идентификаторами их владельцев (своеобразный "стек"). С другой стороны, нужно иметь возможность выбрать весь путь вплоть до корня начиная с произвольного элемента. Это можно сделать написав хранимую процедуру (если ваш SQL-сервер поддерживает стандарт ANSI SQL 3 в части хранимых процедур (PSM) и позволяет из хранимых процедур возвращать наборы записей). Вот как выглядит такая процедура для InterBase:
CREATE PROCEDURE GETPARENTS (ID INTEGER)
RETURNS (DID INTEGER, OID INTEGER, NAME VARCHAR(30))
AS
BEGIN
WHILE (:ID > 0) DO /* ищем до корня */
BEGIN
SELECT O.ID, O.PARENT, O.NAME
FROM OBJECTS O
WHERE O.ID = :ID
INTO :DID, :OID, :NAME;
ID = :OID; /* код родителя для следующей выборки */
SUSPEND;
END
END
RETURNS (DID INTEGER, OID INTEGER, NAME VARCHAR(30))
AS
BEGIN
WHILE (:ID > 0) DO /* ищем до корня */
BEGIN
SELECT O.ID, O.PARENT, O.NAME
FROM OBJECTS O
WHERE O.ID = :ID
INTO :DID, :OID, :NAME;
ID = :OID; /* код родителя для следующей выборки */
SUSPEND;
END
END
В процедуру передается идентификатор, с которого нужно подниматься “вверх” по дереву. В цикле, пока идентификатор не стал равным 0 (не поднялись выше корневого элемента) происходит выборка записи с указанным идентификатором, затем идентификатор меняется на идентификатор родителя.
Выполнение этой процедуры для наших данных привело бы к следующему результату (запрос SELECT * FROM GETPARENTS 4):
4 3 Потомок3
3 1 Потомок2
1 0 Родитель1
3 1 Потомок2
1 0 Родитель1
Соединяя поля "NAME" справа налево мы получим полный "путь" от текущего элемента до корня: “Родитель1/Потомок2/Потомок3”. Этот путь можно использовать либо для показа пользователю, либо для внутренних целей приложения.
Визуализация древовидной структуры
Для визуализации подобной структуры можно воспользоваться компонентом TTreeView, поставляемым в Delphi 2.0 и 3.0. Этот компонент формирует представление типа "outline" при помощи объектов TTreeNode. К сожалению, с этим типом объекта работать не очень удобно, поскольку он произведен от стандартного элемента GUI и при разработке нельзя использовать наследование. Для хранения дополнительных данных узла дерева приходится использовать поле TTreeNode.Data, представляющее собой указатель на произвольный объект или структуру данных.
Рис. 4
При отображении небольшого количества записей (до 1000) можно считывать в память всю таблицу и формировать TTreeView в памяти, не обращаясь затем к базе данных. Однако если нужно периодически перечитывать "дерево", то такой подход будет слишком медленным. Оптимальным было бы перечитывание только раскрываемой ветви дерева. При этом перечитывание будет происходить максимально быстро, т. к. даже самая сложная древовидная структура содержит максимум 200-500 элементов в одной ветви.
Для реализации перечитывания записей по "распахиванию" ветви дерева можно использовать приведенный выше запрос с выборкой элементов одной ветви.
procedure TMainForm.NodeViewExpanding(Sender: TObject; Node: TTreeNode;
var AllowExpansion: Boolean);
begin
GetExpandingItems(Node);
end;
var AllowExpansion: Boolean);
begin
GetExpandingItems(Node);
end;
Допустим, что у нас на форме есть компонент Query1, который содержит запрос
SELECT * FROM OBJECTS
WHERE PARENT = :Parent
WHERE PARENT = :Parent
Процедура GetExpandingItems может быть реализована следующим образом:
procedure TMainForm.GetExpandingItems(var Node: TTreeNode)
var NewNode: TTreeNode;
begin
{ если не передан "раскрываемый" узел, то это самый первый узел.
иначе нужно в качестве Parent передать в запрос идентификатор
элемента, который мы не совсем корректно будем хранить в
Node.Data как целое число, а не как указатель на структуру данных}
if Node = nil then
Query1.ParamByName('Parent').asInteger:=0
else
begin
Query1.ParamByName('Parent').asInteger:=integer(Node.Data);
Node.DeleteChildren; { удалить "подэлементы" если они были }
end;
Query1.Open;
Query1.First;
while not Query1.EOF do
begin
NewNode:=TreeView1.Items.AddChildObject(Query1.FieldByName('NAME').asString)
integer(NewNode.Data):=Query1.FieldByName('ID').asInteger;
Query1.Next;
end;
Query.Close;
end;
var NewNode: TTreeNode;
begin
{ если не передан "раскрываемый" узел, то это самый первый узел.
иначе нужно в качестве Parent передать в запрос идентификатор
элемента, который мы не совсем корректно будем хранить в
Node.Data как целое число, а не как указатель на структуру данных}
if Node = nil then
Query1.ParamByName('Parent').asInteger:=0
else
begin
Query1.ParamByName('Parent').asInteger:=integer(Node.Data);
Node.DeleteChildren; { удалить "подэлементы" если они были }
end;
Query1.Open;
Query1.First;
while not Query1.EOF do
begin
NewNode:=TreeView1.Items.AddChildObject(Query1.FieldByName('NAME').asString)
integer(NewNode.Data):=Query1.FieldByName('ID').asInteger;
Query1.Next;
end;
Query.Close;
end;
После выполнения этой функции создаются элементы, дочерние для указанного Node, или корневые элементы, если Node=nil.
Однако в этом случае структура данных таблицы OBJECTS не дает нам возможности узнать (без дополнительного запроса) есть ли у элемента его "подэлементы". И TreeView для всех элементов не будет показывать признак “раскрываемости” или значок “+”.
Для этих целей без расширения нашей структуры данных не обойтись. Очевидно необходимо добавить в таблицу OBJECTS поле, которое будет содержать количество дочерних элементов (0 или больше). Такое поле можно добавить
ALTER TABLE OBJECTS ADD CCOUNT INTEGER DEFAULT 0;
Но кто будет модифицировать это поле, записывая туда новое количество дочерних элементов? Можно, конечно, делать это и из клиентского приложения. Однако самым правильным решением будет добавление триггеров на вставку, изменение и удаление записей в таблице OBJECTS.
Триггер по вставке записи должен увеличить количество "детей" у своего родителя:
CREATE TRIGGER TBI_OBJECTS FOR OBJECTS
ACTIVE BEFORE INSERT POSITION 0
AS
BEGIN
UPDATE OBJECTS O
SET O.CCOUNT = O.CCOUNT + 1
WHERE O.ID = new.PARENT;
END
ACTIVE BEFORE INSERT POSITION 0
AS
BEGIN
UPDATE OBJECTS O
SET O.CCOUNT = O.CCOUNT + 1
WHERE O.ID = new.PARENT;
END
Триггер по изменению проверяет, не меняется ли родитель элемента. Если да, то значит элемент перемещается от одного родителя к другому и нужно соответственно уменьшить CCOUNT у старого и увеличить у нового.
CREATE TRIGGER TBU_OBJECTS FOR OBJECTS
ACTIVE BEFORE UPDATE POSITION 0
AS
BEGIN
if (old.PARENT <> new.PARENT) then
begin
UPDATE OBJECTS O SET O.CCOUNT = O.CCOUNT - 1
WHERE O.ID = old.PARENT;
UPDATE OBJECTS O SET O.CCOUNT = O.CCOUNT + 1
WHERE O.ID = new.PARENT;
end
END
ACTIVE BEFORE UPDATE POSITION 0
AS
BEGIN
if (old.PARENT <> new.PARENT) then
begin
UPDATE OBJECTS O SET O.CCOUNT = O.CCOUNT - 1
WHERE O.ID = old.PARENT;
UPDATE OBJECTS O SET O.CCOUNT = O.CCOUNT + 1
WHERE O.ID = new.PARENT;
end
END
При удалении нужно уменьшить количество “детей” у владельца:
CREATE TRIGGER TBD_OBJECTS FOR OBJECTS
ACTIVE BEFORE DELETE POSITION 0
AS
BEGIN
UPDATE OBJECTS O
SET O.CCOUNT = O.CCOUNT - 1
WHERE O.ID = old.PARENT;
END
ACTIVE BEFORE DELETE POSITION 0
AS
BEGIN
UPDATE OBJECTS O
SET O.CCOUNT = O.CCOUNT - 1
WHERE O.ID = old.PARENT;
END
(Обратите внимание, что во всех триггерах при обращении к таблице используетс псевдоним O, а для полей в триггере используется уточнитель new. или old. Это сделано для того, чтобы SQL-сервер не перепутал изменяемые поля в UPDATE и поля таблицы в контексте триггера).
Теперь таблица OBJECTS полностью автоматически отслеживает количество "детей" у каждого элемента.
Внимание! Данная реализация отслеживания количества дочерних элементов приводит к тому, что одновременное добавление двух элементов к одному родителю приведет к блокировке (deadlock) обновления родительской записи. В многопользовательской среде такую ситуацию надо предусматривать, например, стараться делать добавление/удаление или перенос элементов в максимально коротких транзакциях read_committed, а при возникновении блокировки попытаться еще раз выполнить операцию без вывода сообщения об ошибке пользователю. Дополнительно см. "Перенос элементов" во второй части статьи.
Для того чтобы TTreeNode "знал" о наличии у него детей, поле Data должно уже указывать на некую структуру данных. Нам нужно хранить идентификатор узла, на всякий случай идентификатор родителя, и количество дочерних записей, а текст (NAME) можно хранить в TTreeNode, как это сделано в приведенном выше примере. Итак, создадим дополнительную структуру:
type
PItemRec = ^ItemRec;
ItemRec = record
Id : integer;
Parent: integer;
CСount: integer;
end;
PItemRec = ^ItemRec;
ItemRec = record
Id : integer;
Parent: integer;
CСount: integer;
end;
При создании нового TreeNode нам придется теперь распределять память для ItemRec
...
var R: PItemRec;
...
NewNode:=TreeView1.Items.AddChildObject(Query1.FieldByName('NAME').asString);
New(R);
NewNode.Data:=R;
R^.Id:=Query1.FieldByName('ID').asInteger;
R^.Parent:=Query1.FieldByName('PARENT').asInteger;
R^.CCount:=Query1.FieldByName('CCOUNT').asInteger;
NewNode.HasChildren:=R^.CCount > 0;
...
var R: PItemRec;
...
NewNode:=TreeView1.Items.AddChildObject(Query1.FieldByName('NAME').asString);
New(R);
NewNode.Data:=R;
R^.Id:=Query1.FieldByName('ID').asInteger;
R^.Parent:=Query1.FieldByName('PARENT').asInteger;
R^.CCount:=Query1.FieldByName('CCOUNT').asInteger;
NewNode.HasChildren:=R^.CCount > 0;
...
(Для того чтобы правильно освобождать память, занимаемую операцией New(R), необходимо в методе TTreeView.OnDeletion написать одну строку – Dispose(PItemRec(Node.Data); Это освободит занятую память при удалении любого элемента TTreeNode или группы элементов).
Свойство HasChildren приведет к автоматической прорисовке значка "+" в TreeView у элемента, который имеет дочерние элементы. Таким образом мы получаем представление дерева без необходимости считывать все его элементы сразу.
Продолжение – часть 2