 En
EnСпособы оценки производительности приложений и серверов СУБД Firebird и InterBase
KDV, iBase.ru, 22.08.2011, последнее обновление – 02.11.2015.
28.10.2021 - добавлены комментарии по некоторым пунктам (актуализация на 2021 год)
Статья предполагает исключительно последовательное чтение, поэтому в содержании нет ссылок внутрь статьи.
- Введение
- Из чего состоит производительность?
- Аппаратное обеспечение
- Процессор
- Память
- Диск
- Транзакции
- Версионность
- Запросы
- Отслеживание insert/update/delete
- Аппаратное обеспечение
- Для дополнительного чтения
Введение
Компания iBase.ru была организована в 2002 году, и ее основной задачей является оказание консультаций в отношении СУБД InterBase и Firebird. Одновременно с iBase.ru была создана компания IBSurgeon, для аналогичной работы на зарубежном рынке.За прошедшие 11 лет мы разработали уникальные инструменты и методики для анализа разных аспектов производительности систем на Firebird и InterBase.
Вам предлагается статья, которая описывает последовательный подход к анализу производительности конкретной системы, который мы используем в своей работе.
Из чего состоит производительность?
Производительность конкретной системы зависит от аппаратного и программного обеспечения. То есть, что делает программное обеспечение, и как на это реагирует "железо". Причины плохой производительности могут быть с обеих сторон – слабая дисковая подсистема, мало памяти, плохое управление транзакциями в приложении, плохие запросы. Также, разумеется, источником плохой производительности могут быть и сторонние приложения, работающие на сервере (или с сервером) – часто небольшие компании вкладывают имеющиеся деньги в один сервер, и громоздят на него все что попало, расчитывая что "сервер выдержит" (не зря же на него столько денег потрачено).Firebird и InterBase, к счастью, не требуют использования "серверных" операционных систем, поэтому часто можно в качестве сервера использовать отдельный компьютер, собранный (или купленный) исключительно под сервер БД.
Выяснить заранее, какого "железа" хватит для системы, весьма сложно, и зачастую невозможно. Для этого нужно иметь какие-то сравнительные параметры, или как минимум начальные требования к системе.
Далее будут приведены общие характеристики, необходимые для функционирования любой системы на Firebird и InterBase. Вы сможете определить, хватает ли вам вашего сервера, что можно улучшить, или, как минимум, на чем заострить внимание при покупке сервера для новой системы.
Аппаратное обеспечение
Процессор
СУБД не является "вычислительной" системой, поэтому процессор на производительность СУБД особого влияния не оказывает. Разумеется, есть два полярных типа запросов – которые загружают диск, и которые загружают процессор. Но реальные системы обычно редко имеют сильный перекос только в одну сторону.Для работы с большим количеством пользователей (50 и более) значение имеет количество ядер/процессоров и способность архитектуры СУБД распараллеливать запросы пользователей по этим ядрам. Общие советы на эту тему можно свести в таблицу:
Под "пользователями" здесь и далее имеется в виду количество коннектов к серверу, в которых одновременно выполняются какие-то действия. Для Classic это, соответственно, равно количеству процессов fb_inet_server на сервере.
| СУБД | Архитектура | Оптимальное количество ядер | Комментарий |
|---|---|---|---|
| Firebird SuperServer, все версии (кроме 3.0) InterBase SuperServer ниже версии 7.0 |
SuperServer | 1 | Изначально разработанное в InterBase 4.2 (в 1994 году) ядро SuperServer не в состоянии использовать более 1 ядра (или процессора). В некоторых случаях приходилось явно привязывать процесс ibserver.exe/fbserver.exe к одному ядру/процессору для исключения потерь в производительности до 10% из-за переключения процесса операционной системой между ядрами/процессорами. Firebird 2.5 SuperServer умеет использовать по 1 ядру на каждую базу данных, но к одной базе данных все обращения будут выполняться только на 1 ядре. |
| Firebird Classic 1.0-1.5 | Classic | 2-6-8 | Эти версии не способны эффективно использовать более 8 ядер (под любой ОС). |
| InterBase SuperServer 7.x, 2007, 2009, XE | SuperServer | 1-8-16 | В InterBase архитектура SuperServer изменена начиная с версии 7.5, которая поддерживает SMP. Начиная с 2007 появилась лицензия InterBase SMP, которая использовала до 8 ядер включительно по умолчанию. Для использования большего количества ядер/процессоров требуется покупка дополнительных процессорных лицензий (по 8 ядер на 1 лицензию). |
| Firebird 2.x | Classic, SuperClassic (2.5) |
2-24 | Более 24 ядер практического смысла не имеют, т. к. возникает серьезная нагрузка на шину процессора, поскольку основной деятельностью СУБД является обмен процессор-память и память-диск. |
| Firebird 3.0 | SuperServer | 2-24 | Наиболее оптимальная архитектура в версии 3.0, с распараллеливанием по ядрам, общим кэшем, и т. д. Имеет существенно более высокую производительность, чем Classic и SuperClassic этой же версии. |
28.10.2021: есть статья двухлетней давности "Тюнинг Firebird и Linux для БД размером 691 гигабайт с 1000+ пользователей". Там можете посмотреть, какое железо используется сейчас для нагруженных систем с Firebird.
HyperThreading
Для приложений (в том числе Firebird) нет разницы в физических процессорах или ядрах. Например, 8 одноядерных процессоров или один 8-ядерный, или один 4-х ядерный с включенным HyperThreading (в результате чего будет 8 якобы ядер) будут выглядеть в операционной системе как 8 отдельных "процессоров". И операционная система будет сама раскладывать процессы по этим "ядрам/процессорам". Производительность в данном случае будет зависеть только от "железа", и разница между "ядрами" может быть разве только при включении HyperThreading (как лучше, так и хуже).
Когда компания Intel впервые представила технологию HyperThreading, то есть, два виртуальных ядра на одно физическое, или удвоение числа физических ядер, технология оказалась сомнительной, и выигрыш в производительности давала только для десктопных компьютеров. В 2004 году мы даже опубликовали статью, в которой были перечислены все недостатки HyperThreading на тот момент.
Затем Intel некоторое время производила процессоры без этой технологии. А потом опять ее внедрила в процессоры, начиная с i3. Не смотря на избавление в новых процессорах от практически всех старых проблем с HyperThreading, эта технология до сих пор имеет смысл только для многопоточных приложений.
В зависимости от архитектуры Firebird или InterBase (SuperServer, Classic) HyperThreading может дать небольшое увеличение производительности, или наоборот, ухудшение. Поэтому, если ваш процессор поддерживает эту технологию, рекомендуем проверить оба варианта, чтобы не потерять производительность. HyperThreading включается и выключается в bios компьютера.
Память
Необходимое количество памяти напрямую зависит как от архитектуры, так и от разрядности сервера (и ОС).SuperServer – является одним процессом и имеет общий кэш БД. При этом нужно учитывать, что 32-разрядный процесс под ОС любой разрядности не может занимать более 3 гигабайт памяти. Максимальный размер кэша у разных версий Firebird и InterBase отличается. Например,
- InterBase 2009 – 131000
- InterBase XE – 750000
В 64-разрядных Firebird и InterBase XE можно задать размер кэша в страницах до 2 миллиардов и 75 миллионов, соответственно.
64-разрядный Firebird SuperServer до версии 2.5 не мог аллокировать более 2 гигабайт RAM для кэша (CORE-1687).
Следовательно, для 32-разрядного SuperServer (Firebird или InterBase) достаточно компьютера с 4-6 гигабайтами RAM, если на этом компьютере более не выполняются никакие другие задачи. Для 64-разрядного уже нужно смотреть, сколько у вас есть памяти, и сколько вы хотите "отдать" под кэш.
28.10.2021: в настоящее время Firebird 3.0 для нагруженных систем чаще используется в режиме SuperServer (64bit).
Classic – по процессу на пользователя/коннект. Разрядность Firebird (32 или 64 бит) в данном случае особого значения не имеет (кроме разве что факта, что 32битный процесс классика вряд-ли стоит конфигурировать на использование 2х гигабайт памяти под сортировки), важнее разрядность ОС и ее возможность использовать более 4 гигабайт памяти. (Впрочем, в начале 2000 у Classic на 32-разрядных Windows, поддерживавших более 4 гигабайт RAM, существовала проблема – процессы могли "падать", если работали выше границы 4 гигабайт. Сейчас либо эта проблема исправлена еще в середине двухтысячных, либо при использовании RAM более 4 гигабайт люди сразу используют 64-разрядные операционные системы.)
Есть сообщения, что потребление памяти процессом Classic увеличилось почти в 2 раза между версиями 2.1.x и 2.5.x. Например, 2.1.3 в конкретной ситуации потреблял 73 мб, а в 2.5.1 – 116мб.
Каждый процесс классика распределяет в памяти свой собственный кэш, поэтому (и не только) размер кэша не рекомендуется устанавливать более 2048 страниц.
Внимание! По умолчанию, если не менять firebird.conf, размер кэша классика (на процесс) составляет всего 75 страниц, что очень мало. В настоящее время рекомендуется явно устанавливать размер кэша классика равным от 512 до 2048 страниц, причем, увы, это значение придется подбирать экспериментально, потому как при большом количестве пользователей в большом кэше Classic страницы чаще становятся неактуальными, что приводит к повторам i/o (чтения измененных другими процессами страниц) и ухудшению производительности.
Для страницы 16к размер кэша в 2048 страниц будет 32 мегабайта памяти на процесс. В промышленных системах размер памяти, занимаемой процессом классика, может быть примерно от 50 до 250 мегабайт (в зависимости от выполняемых запросов, сортировок, объема метаданных, и т. п.). Следовательно, общее потребление памяти можно вычислить умножением значения для одного процесса на количество пользователей.Например, если процесс классика занимает в памяти 150 мегабайт, и предполагается до 200 пользователей, то памяти на сервере нужно не менее 30 гигабайт.
Как выяснить заранее, сколько памяти будет занимать процесс классика? Никак, потому что это зависит от метаданных, запросов, и объема обрабатываемых данных. Нужно запустить Firebird Classic, и посмотреть на размер процесса при выполнении запросов (или работе приложения) к конкретной БД.
SuperClassic – промежуточная архитектура, введенная в Firebird 2.5. Это один процесс, как SuperServer, но внутри него каждый пользователь представлен "как бы процессом Classic", то есть с раздельным кэшем данных, метаданных, и т. п. Общим в SuperClassic 2.5 является только память сортировок (создание или перестройка индексов и запросы с PLAN SORT). Потребление памяти "на пользователя" здесь несколько меньше, чем в обычном Classic, но для подсчета общего объема, занимаемого SuperClassic, по прежнему требуется умножение. Соответственно, нужно аккуратно вычислять потребление памяти, чтобы для 32-разрядного Firebird SuperClassic не превысить 2 гигабайта (например, 20 пользователей по 100 мегабайт). Более разумным для SuperClassic является использование 64 разрядного Firebird, так как уже при 20 пользователях по 100 мегабайт процесс SC будет занимать 2 гигабайта, что недалеко от краха по нехватке памяти для 32-разрядного процесса.
Мониторинг памяти можно осуществлять при помощи Диспетчера задач (TaskManager), однако более удобным является ProcessExplorer. В нем можно сохранить текущее состояние памяти сервера, затем экспортировать эти данные в текстовый файл, после чего их можно импортировать в Excel, и анализировать состояние сервера при помощи сводных таблиц. При использовании СУБД на "общем компьютере" это является фактически обязательным, т. к. позволяет понять потребление памяти, процессора и дисковой активности разными процессами, и выяснить, что именно является причиной проблем с производительностью.
Также в качестве инструмента мониторинга памяти рекомендуем RAMMAP. Этой утилитой также можно посмотреть, сколько от базы данных загружено в кэш файловой системы Windows.
Внимание! Достоверно известна проблема с Firebird на Windows 64 bit – если размер БД примерно равен размеру RAM, или меньше (при RAM > 4gb), то с течением времени вся память Windows "уходит" в кэш, и операционная система начинает тормозить.
CORE-3791, исправлено в версиях 2.1.5, 2.5.2.
CORE-3791, исправлено в версиях 2.1.5, 2.5.2.
Диск
Для СУБД на первом месте, как правило, стоит диск. Дисковая подсистема обычно самое слабое место как для массово распространяемых приложений на Firebird и InterBase, так и для серверов, используемых в организации "для всего". И в России, и за рубежом, не редки случаи, когда "сервером" называют компьютер с одним sata-диском.Диски (одиночные, raid-масивы, hdd и ssd) имеют 2 основных характеристики – это Transfer rate, т. е. скорость передачи данных при последовательном доступе, и IOPS – операций в секунду, важный параметр для оценки скорости случайного доступа.
Я бы рекомендовал начать оценку диска (или массива) при помощи утилиты HDTune.
Вот типичная картинка десктопного диска Hitachi 500gb, SATA II:
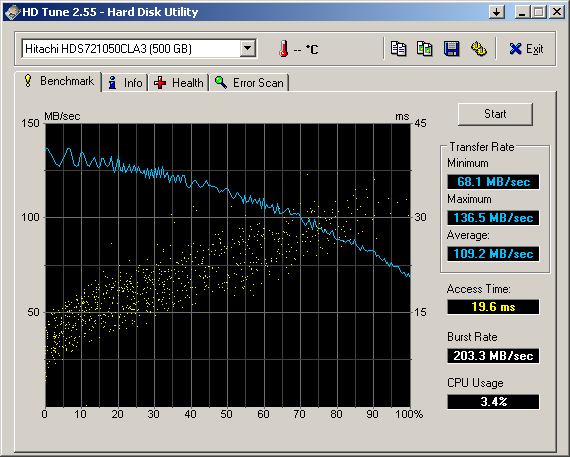
Transfer rate, как видите, у этого диска от 70 до 136 мегабайт в секунду. Это типично для современных SATA (на 2011 год), и если у вашего диска эти данные намного хуже, то есть несколько вариантов:
- это устаревший диск
- если на синей линии есть провалы, то либо во время теста были обращения других программ к диску, либо диск в некоторых местах начинает "умирать" (и нужно планировать его замену – пример)
- отсутствуют правильные драйверы дисковой подсистемы
- в bios неверно определяется интерфейс диска, проблемы с кабелем, и т. п.
- если линия transfer rate горизонтальна, и явно ниже 100мб в секунду, то это значит что пропускная способность интерфейса с диском установлена в bios или контроллере значительно ниже, чем может обеспечить диск (либо есть проблемы с контроллером диска или raid).
{kind=link}
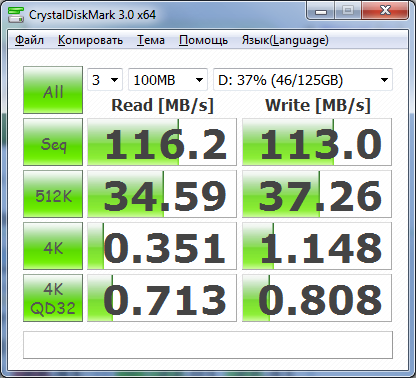
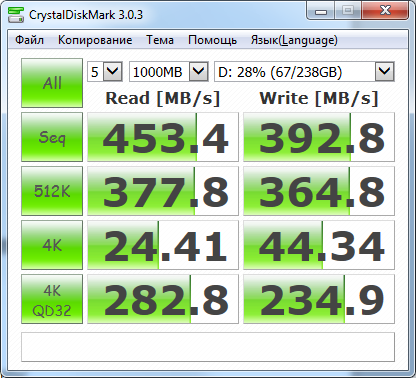
Слева – типичный десктопный HDD SATA II, справа – SSD Plextor M6S Pro.
28.10.2021: сейчас вполне можно купить SSD со скоростями до 3х гигабайт в секунду как на чтение, так и на запись. Однако в этом случае есть шанс "недоиспользования" производительности диска, т.к. Firebird может начать упираться в процессор. Например, для скорости бэкапа (а он он производится на 1м ядре процессора, если только это не HQbird с возможностью распараллеливания бэкапа) не будет никакой разницы между SSD со скоростью чтения/записи в 600мб/сек или 3000мб/сек.
Более подробную информацию утилита выдает в пункте меню "Копировать". В скопированном тексте вы увидите iops и мб/сек для всех режимов этого теста. В качестве более сложного инструмента можно использовать и IOMeter (для Windows и Linux).
На картинках видно, что скорость последовательной записи чуть меньше скорости чтения. Это нормально (для raid 10 из жестких дисков скорость записи бывает выше скорости чтения). Но для RAID-массива, особенно "предустановленного поставщиком сервера", скорость записи по умолчанию может оказаться весьма низкой (до 3 мегабайт в секунду, что никуда не годится). Причина – выключенный кэш записи RAID. Включить кэш записи можно установив утилиту производителя по управлению данной моделью RAID. В свойствах драйвера или в bios как правило это сделать невозможно (в свойствах драйвера кэш включается обычно для IDE/SATA-дисков).
Также, кэш записи диска/raid будет принудительно выключен, если компьютер является контроллером домена, или контроллер raid не имеет "батарейки".
Оценивать скорость дисковой подсистемы в работе под Windows нужно при помощи PerfMon (на Linux штатные средства для этого весьма убоги, нужно искать какой-либо эквивалент perfmon-у). В качестве примера – картинка создания индекса (фаза переноса данных из базы в TEMP) из статьи о тестировании терабайтной базы данных:
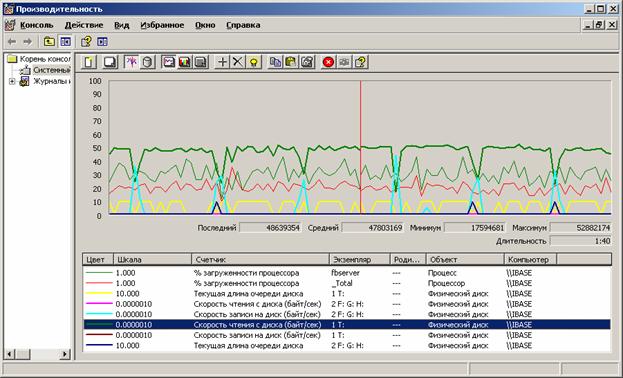
Основные параметры, которые нужно проверять для диска – скорость чтения (байт/сек), скорость записи (байт/сек), текущая длина очереди диска.
28.10.2021: в Windows 10 и выше (и аналогичных серверных ОС) perfmon запускается или из cmd, или через Run - perfmon.msc.
На картинке видно, что в процессе создания индекса данные читаются из БД (с диска T) со скоростью около 50 мегабайт в секунду (зеленая линия). Запись на диск TEMP (H) происходит порциями, со скоростью до 30 мегабайт в секунду (голубая линия). Очередь диска T периодически достигает 1, такого же значения очередь диска H достигает значительно реже.
Текущая длина очереди диска – это сколько команд стоит в очереди на выполнение. Если вы видите, что очередь диска часто доходит до 2-3 или выше, то это значит, что диск не справляется с потоком команд, и является узким местом в производительности системы.
Поскольку обращения сервера к базе данных в большинстве случаев представляют собой случайный доступ, то чем больше IOPS у конкретного диска, тем меньше шансов, что очередь диска будет высокой. Как уже было сказано выше, у обычных одиночных SATA IOPS редко превышает 150 (у SAS – 175-200), при этом SSD диски и дорогие RAID-массивы имеют IOPS измеряемый тысячами и десятками тысяч.
В качестве еще одной оценки производительности диска можно использовать тест скорости restoreLINK.
Рекомендуем также прочитать статью "Как правильно мерять производительность диска".
Некоторые дисковые банальности
При покупке или самосборке компьютера для СУБД нужно учитывать ряд факторов, которые являются достаточно очевидными, но почему-то упускаются весьма часто. Наиболее характерные примеры подобных случаев:- для СУБД выделяется один диск, на котором все – база, бэкапы и т. д.
- на компьютере один raid, опять же, для всего – ОС, temp, БД, бэкапы...
Например, если используется один диск для (пусть даже и raid) БД и бэкапов, то это снижает скорость резервного копирования (и восстановления) от 30 до 50%.
Также, для сортировок и при создании индексов (в т. ч. при restore) Firebird и InterBase используют temp. Поэтому физический ввод-вывод работы с БД, backup/restore и temp лучше разделять. Грубо говоря, в минимальной и дешевой конфигурации должно быть 3 жестких (или ssd) диска – 1 для ОС, виртуальной памяти и temp, 2 для БД, и 3 для резервных копий.
RAID
На текущий момент оптимальным массивом для СУБД является RAID 10. RAID 5 уже давно "забракован", как минимум для СУБД. Существует интересный сайт www.baarf.com, на котором собрана информация о всех недостатках RAID 5. Также см. статьи RAID-5 must die! и информацию о статистике по потерям данных на raid 5, 6 и 10.RAID 0 категорически не рекомендуется использовать ни для чего, кроме как для TEMP или хранения любой другой информации, которую не жалко потерять. Несмотря на очевидность ненадежности RAID 0 в интернете часто встречаются идеи разместить базу данных на таком RAID. Иногда и поставщики техники устраивают "сюрпризы" покупателям, поставляя сервера с двумя SSD, объединенными в RAID 0, на который уже установлена операционная система.
SSD
При наличии проблем с производительностью, связанных именно с дисковой подсистемой, для ряда пользователей, которые не имеют возможности оптимизировать саму базу или приложения (купленные решения), приемлемым и единственным выходом является размещение базы данных на SSD (хотя бы RAID 1 из таких дисков). Это даст сильное ускорение, т. к. выше уже было отмечено, что по IOPS диски SSD гораздо лучше чем HDD, и позволит отложить проблемы на некоторое время (может быть даже год, два или три). Конечно, это слишком грубое решение, но если у компании нет исходных текстов приложения и специалистов по СУБД, то остается только оно.На картинках, приведенных выше, вы можете оценить разницу между десктопным SATA II HDD и SSD.
Файловые системы с журналированием
Документальных подтверждений нет, но существует мнение, что для баз данных InterBase и Firebird (возможно и для других СУБД) журналируемые файловые системы повышают шансы повреждения БД в случае сбоя ОС или железа. Также дополнительные операции файловой системы ухудшат производительность СУБД. Поэтому журналирование в файловой системе или нужно выключать, или использовать файловую систему без журналирования. Оставьте эту функциональность для серверов, хранящих множество файлов.У InterBase, начиная с 2007 версии, есть собственный механизм журналирования.
Транзакции
Приложения стартуют транзакции для выполнения определенных действий. Поэтому, по количеству выполняемых транзакций можно косвенно определить, какую нагрузку над базой данных производят приложения. Для мониторинга количества транзакций и их состояния мы разработали инструмент IBTM (IBSurgeon Transaction Monitor). Монитор способен собирать информацию о транзакциях, используя универсальный для Firebird и InterBase способ, а также специфичные для Firebird и InterBase механизмы.Дистрибутив пробной версии IBTM
28.10.2021: разработка IBTM прекращена уже 6 лет как. Аналог есть в HQbird.
Смысл IBTM прост – на сервере, или отдельном компьютере (который работает в те же интервалы времени, что и сервер), работает монитор, который обращается к указанной базе данных 1 раз в минуту (это наиболее информативный интервал), и сохраняет состояние транзакций в текстовом файле с расширением tmd. Сохраняются номера Next transaction, Oldest Active, Oldest Snapshot и Oldest transaction, то есть то, что вы можете видеть в выдаче gstat -h <файл_базы>. Например,
Database "....gdb"
Database header page information:
Flags 0
Checksum 12345
Generation 3329337
Page size 8192
ODS version 10.1
Oldest transaction 1608100
Oldest active 1630966
Oldest snapshot 1489780
Next transaction 3329328
Bumped transaction 1
Sequence number 0
Next attachment ID 0
Implementation ID 19
Shadow count 0
Page buffers 0
Next header page 0
Database dialect 3
Creation date Dec 22, 2008 23:34:00
Attributes force write
Variable header data:
Sweep interval: 20000
*END*
Flags 0
Checksum 12345
Generation 3329337
Page size 8192
ODS version 10.1
Oldest transaction 1608100
Oldest active 1630966
Oldest snapshot 1489780
Next transaction 3329328
Bumped transaction 1
Sequence number 0
Next attachment ID 0
Implementation ID 19
Shadow count 0
Page buffers 0
Next header page 0
Database dialect 3
Creation date Dec 22, 2008 23:34:00
Attributes force write
Variable header data:
Sweep interval: 20000
*END*
В tmd сохраняются 4 выделенных жирным шрифтом значения, плюс, если указан специфичный для сервера метод получения информации (Firebird API или InterBase tmp$), сохраняется количество активных на данный момент транзакций (разница между Oldest transaction и Oldest active не является "количеством" активных транзакций).
Ежеминутное снятие состояния транзакций утилитой IBTM никак не нагружает базу данных или сервер, независимо от архитектуры (Classic, SuperServer), это проверено на множестве конфигураций (более 200).
Для понимания картины, происходящей с базой данных в отношении транзакций, необходимо, чтобы монитор проработал как минимум неделю. После этого можно анализировать данные, но выключать монитор не нужно – это поможет периодически проверять состояние сервера, заметить неожиданные увеличения нагрузки, обнаружить проблемы с транзакциями в приложениях и т. д.
Пример картинки:
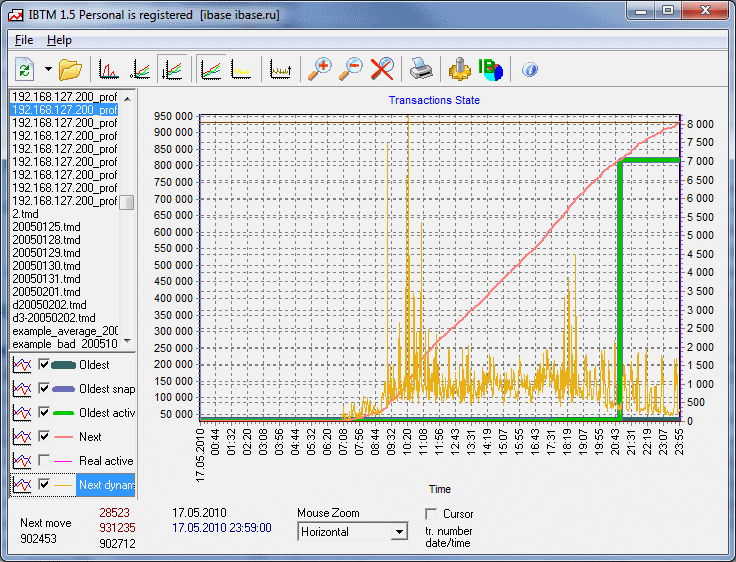
Из данного графика можно сделать следующие выводы:
- работа системы не круглосуточная, начинается в 7 утра, и заканчивается около 20-23 часов.
- интенсивная работа (до 7 тысяч транзакций в минуту) начинается в 9 утра.
- с 11 часов работа стабилизируется. следующий пик интенсивности в 18 часов. средняя загрузка системы - на уровне 1000-1500 транзакций в минуту.
- есть длинные активные транзакции, которые препятствуют сборке мусора. Эти транзакции завершаются примерно в 21 час.
- и т. д.
Версионность
Достаточно одной длинной транзакции read-write, и в таблицах могут накапливаться версии, чтение или обновление которых будет приводить к торможению или из-за сборки записи из версий, или из-за срабатывания кооперативной сборки мусора.Разумеется, версии накапливаются не из-за транзакций как таковых, а из-за обновлений или удалений данных. В тысячи транзакций может не быть обновлений ни одной записи, или наоборот, в одной транзакции может быть обновлен миллион записей.
Если при проверке транзакций IBTM обнаружились длительно работающие транзакции, то имеет смысл снять полную статистику по базе данных
gstat -a -r <файл_бд> >stat.txt
причем, для первого раза желательно получить статистику утром, днем и вечером (безусловно до выполнения регламентного sweep, если таковой в системе выполняется по расписанию). Если база большая, и сбор статистики выполняется долго, вы можете выбрать наиболее удобные моменты для снятия статистики по графику активности системы в IBTM. Например, по графику, приведенному выше, это интервал времени с 11 до 18 часов.Анализировать полученную статистику лучше всего в IBAnalyst, т. к. он не только выводит данные в табличном виде (что может также делать и IBExpert), но и выдает предупреждения, анализируя подозрительные или критические значения, либо их соответствия.
28.10.2021: Свежие версии IBAnalyst (database analyst) есть только в пакетах HQbird. Старая версия IBAnalyst (2.7) не понимает формат статистики Firebird 3, 4, и даже последних версий 2.5.
Пример картинки:
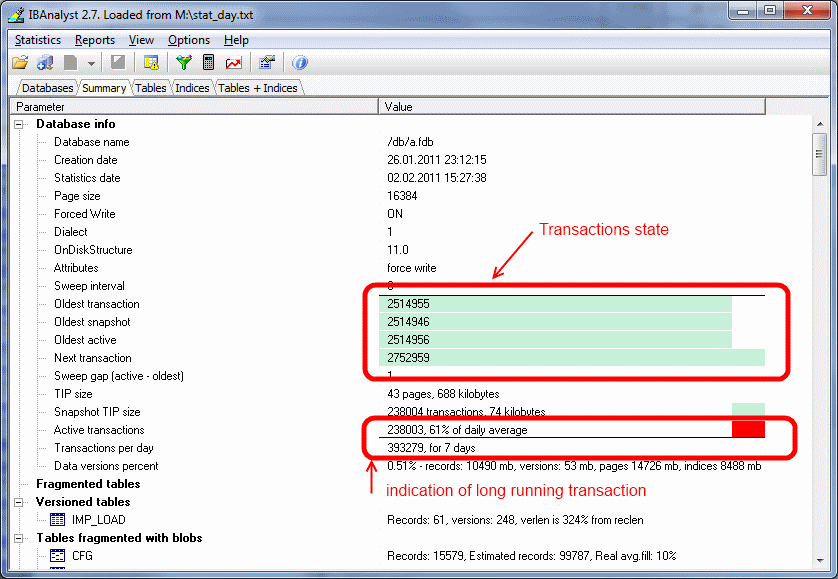
Состояние транзакций кажется нормальным, однако уже две трети рабочего дня существует приложение с активной транзакцией, которая препятствует нормальной сборке мусора. Когда такая транзакция стала активной, можно определить по графику IBTM (см. выше). Если вы работаете с InterBase 7.x и выше, или Firebird 2.1 и выше, то можете использовать запрос к tmp$transactions и mon$transactions соответственно, чтобы найти эту транзакцию и ее соединение, чтобы определить, какая рабочая станция виновата в этом.
Как интерпретировать состояния транзакций на этой странице – описано в справке IBAnalyst по F1. Этот же документ есть на сайтеLINK.
Посмотрев на состояния транзакций (и другую информацию, если нужно), можно перейти к закладке Tables:
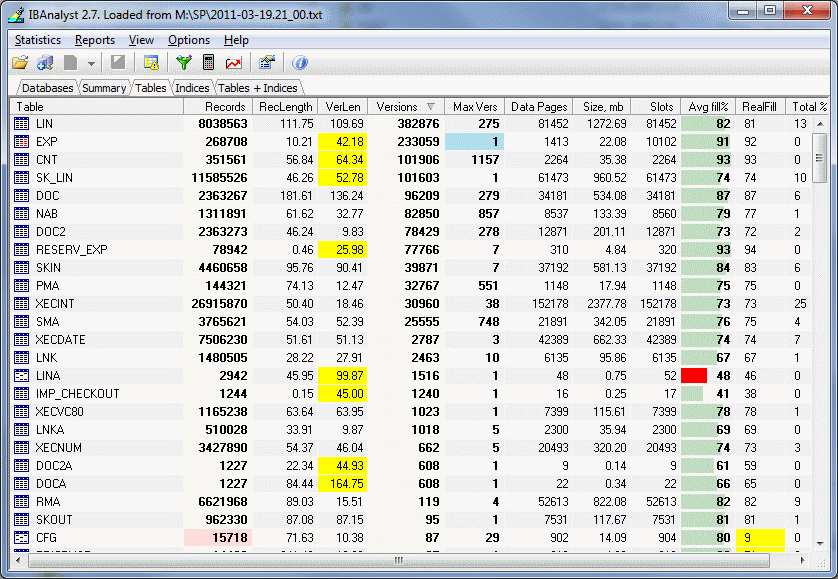
Здесь видно, что
- больше всего версий в таблице LIN. Накопилось 382 тысячи версий, причем есть записи, у которых не менее 275 версий
- в таблице exp произошло массовое удаление записей (удалено 233 тысячи), но версии до сих пор не убраны как мусор
- в таблице cnt версий 20% от количества записей. И есть записи, у которых до 1157 версий
- ...
При помощи IBAnalyst можно увидеть массу другой полезной информации о содержимом БД и явных или потенциальных проблемах производительности, но в данной статье эта тема рассматриваться не будет (полезные советы есть в разделе справки IBAnalyst – F1, Содержание, "Дополнительные вопросы и ответы").
Отслеживание Insert/Update/Delete через триггеры+udf
IBAnalyst показывает накопившиеся версии на конкретный момент, но в нем невозможно понять, откуда взялись эти версии, т. е. какие именно действия привели к накоплению версий в таблицах.28.10.2021: сейчас такой анализ делается при помощи трассировки (trace). Для примера - статья по отлову deadlocks.
Использовать какой-либо репликатор для этих целей достаточно затратно, особенно если речь идет только об одной БД. Поэтому более естественным и интересным методом является использование UDF.
Необходимы следующие действия:
- нужна udf с возможностью записи в текстовый файл (с указанным именем) какой-либо информации. Например, нечто вроде WriteToFile(Filename, Line). Функция должна уметь создавать файл, если его нет, и дозаписывать информацию, если он уже есть.
- Для тех таблиц и действий, которые нам нужно промониторить, создаем триггеры. Для Firebird 2.1/2.5 можно создавать универсальные триггеры, для InterBase придется делать по триггеру на каждое действие. В триггере вызываемая функция должна записывать в файл
- дату-время, имя таблицы, имя триггера, действие (если триггер универсальный), какие-либо данные, например, значение столбца первичного ключа таблицы, и т. д.
Запросы
Определив интенсивность транзакций в системе, накопление (или отсутствие) версий в таблицах, можно перейти к вопросу – какие же запросы приводят к подобному поведению системы? Приложения, разрабатываемые на протяжении как минимум 4-х месяцев, уже могут содержать ошибки в виде лишних транзакций, транзакций с неверными параметрами, лишних запросов, и т. д.Более того, бывают случаи, что пользователи работают с приложением не так, как задумал разработчик, что вызывает неординарное поведение системы.
Как уже упоминалось выше, в определенных целях можно воспользоваться таблицами мониторинга (tmp$ и mon$), однако эти таблицы показывают только снимок состояния сервера на конкретный момент, а не то что происходило на сервере в течение дня.
В Firebird 2.5 можно включить Trace API, но полный лог включать не стоит, и даже лог с одной рабочей станции будет тяжелым для анализа, т. к. вам его придется просматривать в обычном текстовом виде (даже FB Trace Manager не очень поможет).
Наиболее удобным (в общем-то, и единственным для всех InterBase и Firebird 2.1 и ниже) инструментом является FBScanner. Он работает как proxy (между клиентами и сервером), позволяя не только наблюдать в реальном времени выполняемые транзакции и запросы, но и сохранять всю последовательность операций, выполняемых с клиента (включая планы запросов, даже если это не было предусмотрено приложением).
28.10.2021: FBScanner актуален только для старых версий Firebird. Сейчас анализ запросов и нагрузки системы выполняется трассировкой в HQbird - в результате трассировки генерируется отчет с длительными запросами, частыми запросами, и т.д..
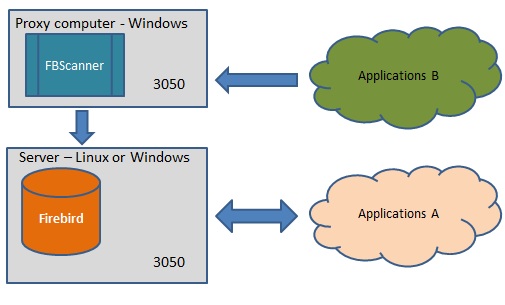
На рисунке приведен один из вариантов работы FBScanner. Приложение B как будто подсоединяется к серверу Firebird, а на самом деле все транслируется через FBScanner. Можно пустить все приложения через FBScanner, но это может привести к замедлению работы (от 5% до 15%) при числе клиентов 100 и больше.
Вот пример лога за 1 рабочий день, 84 компьютера (все соединения шли через FBScanner), до 1350 транзакций в минуту, до 3200 операторов SQL в минуту, и самый долгий запрос выполнялся 50 секунд:
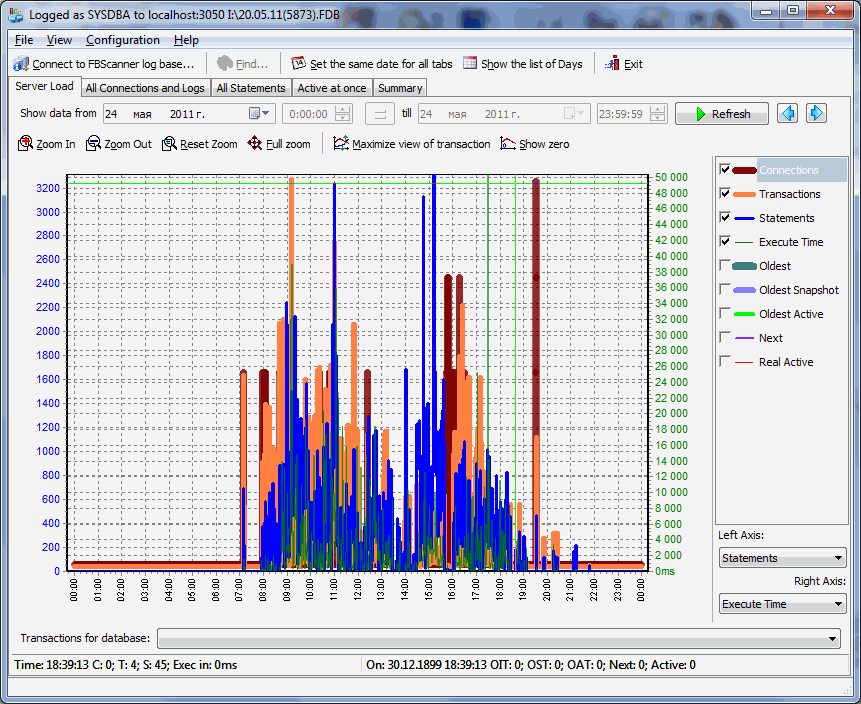
В любой точке этого графика по меню правой кнопки мыши можно переключиться либо на соединения, работавшие в этот момент, либо на sql-операторы, выполнявшиеся в тот момент. Правда, лог 84-х компьютеров тяжело просматривать, хоть FBScanner и позволяет выделять операции, проводившиеся конкретными рабочими станциями, или в конкретных транзакциях.
Куда проще подключить через FBScanner только один компьютер, и изучать одно рабочее место. Кстати, в одной компании так обнаружили, что пользователи "для удобства" запускают на компьютере до трех экземпляров приложения, и работают в них по очереди.
Вот пример лога из одного приложения другой БД:
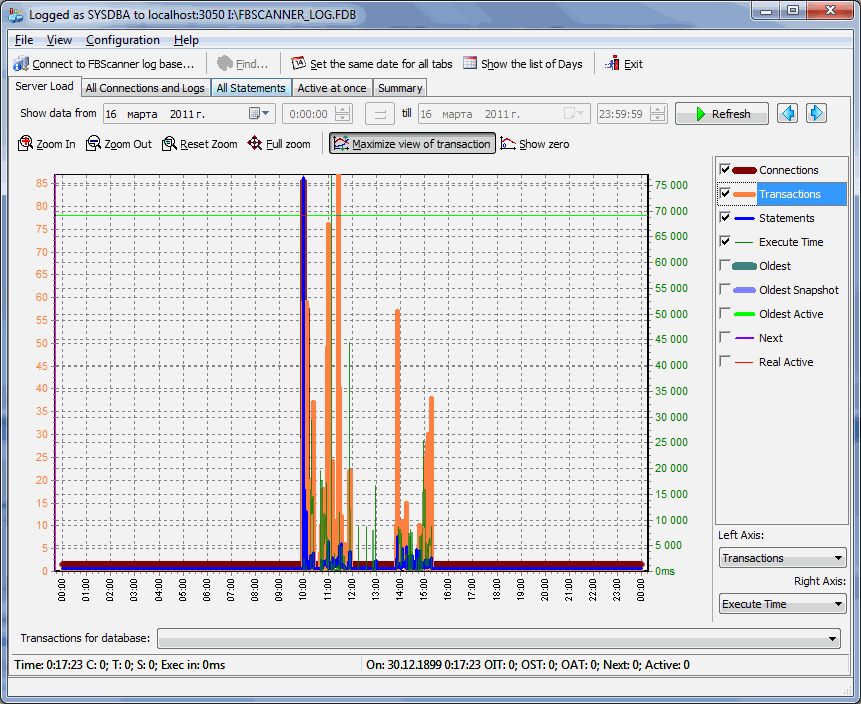
Приложение умудрялось на одном пользователе генерировать до 85 транзакций в минуту. Если переключить Left Axis на Statements, то будет видно, что в пик количества sql-операторов, приходящийся на начало работы приложения, выполняется аж 4200 sql-операторов.
На закладке All Connections and logs можно посмотреть, что это за операторы.
Или, если в Server Load скрыть "мешающие" Connections и Transactions, то останется график с количеством операторов в минуту, и суммарной длительностью выполнения операторов (execute time) за видимый интервал времени.
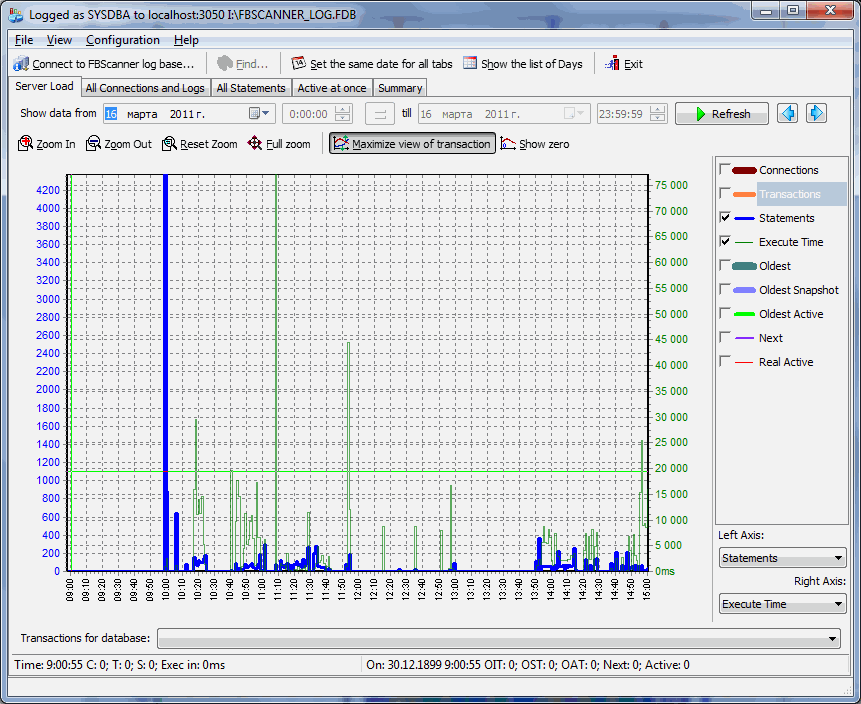
Самый тяжелый sql-оператор, длился 75 секунд (в 11:10). Можно посмотреть, что это был за запрос, в каком коннекте, транзакции, и какие запросы его окружали – в верхней части каждый отдельный коннект содержит суммарную информацию по времени prepare и времени execute, в нижней части – детали по конкретному коннекту.
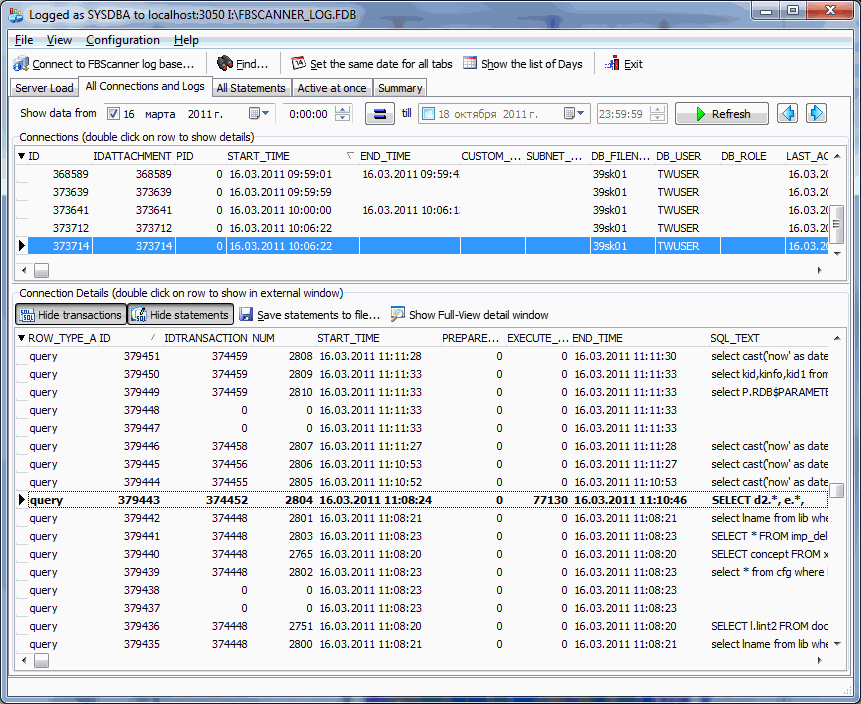
Собственно, ничто не мешает отсортировать любой из видов (выше или ниже) по Execute time, и посмотреть, какие запросы выполнялись медленнее всего, и когда это было. Если вы видите, что время выполнения одного и того же запроса увеличивается с каждым разом – то скорее всего производительность сервера деградирует по какой-либо из причин: увеличение количества пользователей, накопление мусора из-за долгих активных транзакций, и т. п.
Вот общий список всех выполнявшихся последовательно операций:
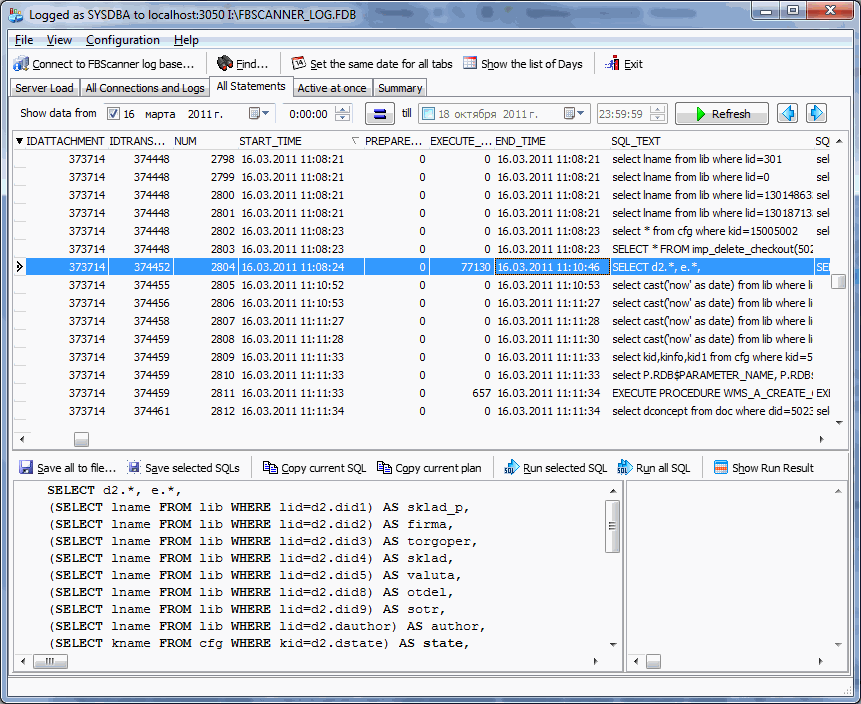
Если при логировании было включено сохранение планов, то FBScanner автоматически при prepare каждого запроса самостоятельно запрашивает у сервера план данного оператора. Это полезно для разных целей:
- найти планы, в которых используется конкретный индекс
- найти планы, в которых не используются конкретные индексы
В общем, при помощи FBScanner можно подробно изучить работу вашего (или даже чужого) приложения, и понять, правильно оно работает (как задумано), или нет. Если нет – возвращаетесь к исходникам приложения, находите "забытые" транзакции, исправляете параметры, запросы, переписываете логику – в общем, делаете все, чтобы ваши приложения работали быстрее.
mon$ и tmp$
В InterBase 7.5 и в Firebird 2.1 появились специальные системные таблицы (tmp$ и mon$, соответственно). Это, собственно, не совсем таблицы, а возможность посмотреть состояние сервера в виде таблиц. Наименования основных таблиц у InterBase и Firebird совпадают. Например, tmp$attachments – это все соединения с сервером, mon$transations – все транзакции, активные в данный момент, mon$statements – все выполняемые или препарированные запросы на данный момент.Содержимое mon$ и tmp$ заполняется в момент первого к ним обращения (к любой mon$/tmp$ таблице), и показывают состояние сервера на этот момент. Если проверять содержимое этих таблиц, например, каждые 5 минут, то мы увидим определенную динамику, но не будем иметь понятия, что происходило в интервале этих 5 минут. Поэтому, для задачи оптимизации запросов рекомендуется использовать уже упомянутые выше в статье инструмент FBScanner или trace/audit в Firebird 2.5.
Тем не менее, при помощи mon$ и tmp$ можно отслеживать наиболее "тяжелые" соединения, длительность транзакций, и многие другие параметры. Запросы к этим таблицам можно выполнять самостоятельно, однако в Firebird таблицы mon$ менее денормализованы, поэтому для получения ценной информации приходится выполнять достаточно сложные join из нескольких таблиц. Для облегчения этой задачи, и одновременно визуализации получаемой информации мы разработали инструмент FBMonLogger (работает только с Firebird).
Примеры выводимой FBMonlogger информации и анализа проблем вы можете увидеть в указанной выше ссылке на продукт.
Для дополнительного чтения
- Process Explorer для Windows
- Профилирование среды выполнения
- Firebird and RAID (English)
- Тест скорости restore Firebird и InterBase
- База данных в 1 терабайт на Firebird – общее описание теста, описание теста с техническими подробностями
- О многоверсионности в двух словах
- Описание методов доступа к данным, используемых ядром Firebird