 En
EnООП в РСУБД
Владимир Котляревский
- Оправдания и благодарности
- Постановка задачи
- RDBMS как хранилище объектов
- Связи между объектами
- Система ограничения доступа
- Вариант реализации клиентской или middle tier библиотеки доступа
- Литература
Оправдания и благодарности
Эта статья большей частью (хотя и не целиком) является компиляцией уже известных методик, хотя много раз оказывалось, что я изобрел уже известный и неплохой велосипед самостоятельно. Я старался давать ссылки на известные мне работы по соответствующей тематике. Если я пропустил чью-то работу в списке литературы, и, таким образом, нарушил чей то copyright, то пишите мне на vlad@contech.tomica.ru – и я извинюсь и дополню статью.Список литературы приведен в порядке всплытия его в моей голове.
Описанные структуры БД являются упрощенными, так, чтобы максимально ясно иллюстрировать рассматриваемые проблемы. Совсем тривиальные моменты вообще опущены из рассмотрения.
Все методики, взятые из литературы, проверялись мной на жизнеспособность. Придуманные мной – тем более.
Скрещивание ООП и РСУБД – всегда компромисс. Я старался рекомендовать методики, где этот компромисс наименее губителен и для того, и для другого. Старался также описывать положительные и отрицательные стороны каждого такого компромисса.
Разумеется, далеко не для каждой задачи подходит описанный здесь объектный подход к проектированию БД (что, впрочем, верно и для ООП вообще – что бы ни говорили его апологеты :-)). Рекомендации к применению – системы хранения и оперирования документами, и все, что с ними связано. Бухгалтерские системы, например.
Благодарности:
- Ded (Александр Невский) – за прочтение и благоприятный отзыв.
- ДК (Дмитрий Кузьменко) – за рецензирование, редактирование и публикацию. И за сайт http://www.ibase.ru. И много еще за что.
Постановка задачи
В чем проблема?
Современные реляционные базы разрабатывались в те времена, когда солнце светило ярче, компьютеры работали медленнее, математика была в почете, а про ООП еще никто не знал. Следствиями этого факта являются следующие характерные черты большинства RDBMS:- Они всем привычны.
- Они быстры – если применять их согласно известным стандартам.
- Они имеют простой, понятный и опробованный десятилетиями способ доступа к данным и манипуляции наборами данных – SQL.
- Они построены на основе строгой математической теории.
- Они удобны для разработки приложений – если приложения разрабатываются так, как это было принято 20-30 лет назад.
Как видно, почти все перечисленные качества являются скорее положительными, кроме, пожалуй, последнего. Сейчас довольно редко можно столкнуться с разработкой ПО (из почти любой области) объемом больше пары тысяч строк кода без применения ООП. ООП давно присутствует в построении визуальных форм – то есть разработке UI. Также все в порядке с возможностью использования ООП на уровне бизнес-логики – если она реализуется на middle-tier или на клиенте. Но вот хранилище данных… Последние 10 лет было много попыток реализовать ОО БД – насколько мне известно, все более-менее неудачные. Их качества – это качества RDBMS наоборот. Они непривычны, медленны, нет стандартного способа доступа, нет математической теории, хотя удобство разработки приложений наверно выше…
Как результат – все продолжают пользоваться RDBMS. И скрещивать ОО бизнес-логику и объекты с реляционным доступом к хранилищу данных, где все эти объекты живут.
Чего хотим?
Таким образом, хотим мы простого – разработать некий набор стандартных способов скрещивания ОО слоя бизнес-логики и реляционного хранилища. То есть – как хранить объекты в реляционной базе, и как реализовать связи между объектами. При этом крайне желательно не потерять те преимущества, которые предоставляются нам реляционными СУБД при традиционном проектировании БД, из которых основные – скорость, гибкость и простота работы с наборами данных.RDBMS как хранилище объектов
Вначале разработаем простейшую структуру БД, которая была бы удобна для реализации поставленной задачи.OID
Объекты уникальны и должны быть легко идентифицируемы, поэтому все объекты, хранящиеся в БД, должны иметь уникальные идентификаторы-ключи из единого множества – так же, как в run-time разные указатели указывают на различные объекты в памяти. Идентификаторы эти используются для ссылок на объекты, для загрузки объекта в run-time представление, etc. В [1] эти идентификаторы называются OID – Object ID, в [2] – UIN, Unique IdeNtifier, или "гиперключ". Будем называть их OID, хотя гиперключ – тоже весьма красивое слово :-).По поводу уникальности. Проектировщикам БД, привыкших к классическому подходу, может показаться странной идея о том, что иногда ключ таблицы имеет смысл сделать уникальным не только в пределах этой таблицы (в терминах ООП – не только в пределах множества объектов некоторого класса), но и в пределах всей БД (всех классов). Однако такая строгая уникальность дает серьезнейшие преимущества, которые очень быстро станут очевидны. Более того, часто имеет смысл обеспечить полную уникальность во Вселенной, что даст немалые преимущества при реализации распределенных БД и репликации. Недостатков же строгая уникальность ключа в пределах БД практически не имеет – за исключением несколько более сложной реализации в случае составного ключа – если оставаться в рамках чисто реляционного подхода, какая разница, уникален суррогатный ключ в пределах только таблицы или всей БД?
OID ни в коем случае не должно иметь естественного значения в реальном мире – то есть это должен быть чисто суррогатный ключ. Я не буду здесь перечислять все доводы за и против суррогатных ключей по сравнению с естественными – заинтересованных можно отослать к статье [4]. Самое элементарное объяснение состоит в том, что все, имеющее отношение к реальному миру, может измениться. Включая номер двигателя, номер сетевой карты, ФИО, номер паспорта, номер карточки социального страхования, и даже пол.
Дату рожденья вот пока еще не научились менять – по крайней мере де-факто. Но она, к сожалению, не уникальна. (Написал вот "к сожалению" – и задумался :-))
Помните? – "все, что может испортиться – портится" ("следствие: то, что не может испортиться,…". хм. Но не будем о грустном :-) ). А это немедленно повлечет за собой изменение всех идентификаторов и ссылок – и, как пишет автор [1] Scott Ambler, к “huge maintenance nightmare”. А суррогатный ключ испортиться не может – по крайней мере, в смысле зависимости от меняющегося мира.
Опять же, никому ведь не приходит в голову требовать, чтобы указатели несли какую-то дополнительную информацию об объекте, кроме адреса памяти. Однако есть люди, которые категорически против суррогатов. Самое блестящее возражение против суррогатов, которое я слышал – "это противоречит реляционной теории". Что весьма спорно, так как в некотором смысле суррогатные ключи куда ближе в ней, чем естественные. Однако – довольно. До сих пор не поучаствовавших или хотя бы не поприсутствовавших при соответствующих holy wars, но искренне заинтресованных темой отсылаем к архивам news://some.usenet-server.com/fido.ru.dbms.sql и news://some.usenet-server.com/fido.ru.dbms.interbase (авторы, насколько мне помнится, большей частью А. Тенцер и А. Усов), а также news://forums.demo.ru/epsilon.public.interbase (А. Усов – но это было давно, и там гораздо меньше).
Интересующихся более строгим обоснованием необходимости OID, обладающего указанными характеристиками (суррогат, уникальный как минимум в пределах БД) можно отослать к [1], [2] и [4], а также и к более специальной литературе :-).
Простейший способ физической реализации OID – поле типа integer и одна функция – генератор уникальных значений этого типа. В больших или распределенных БД, возможно, имеет смысл использовать int64 или комбинацию из нескольких integer. (Имеет также смысл рассмотреть тип UUID (GUID) ?)
ClassId
Все объекты, хранящиеся в БД, должны иметь некий хранимый (persistent) аналог RTTI, немедленно доступный по идентификатору объекта. Тогда, зная OID, и при условии его уникальности в пределах БД, можно немедленно выяснить тип объекта – очень важный момент (как говорил киплинговский удав слоненку – "вот тебе первая выгода" уникальности OID). Эту задачу поможет решить атрибут объекта ClassId, который ссылается на список известных типов – а проще говоря, на таблицу, назовем ее CLASSES. Эта таблица может включать в себя самую разнообразную информацию – начиная просто от имени типа, и заканчивая описаниями метаданных типа, заточенных для предметной области. Позже я приведу примеры организации таблицы classes, а сейчас можно отметить, что описание типа само вполне может быть объектом и иметь OID.Name, Description, creation_date, change_date, owner
Очень удобно, хотя и не всегда необходимо, иметь способ именования объектов, независимый от типа. Например, каждый объект может иметь короткое и длинное имя. Вспомним файловую систему – было бы весьма неудобно вместо имен файлов запоминать их handles или inodes в файловой системе :-). Также бывает удобно для самых разнообразных целей иметь для любого объекта и другие атрибуты, аналогичные файловым – creation_date, change_date, owner. (owner может быть как строкой, содержащей имя владельца, так и ссылкой на объект типа “пользователь”). Также необходим атрибут Deleted – признак удаленности объекта. Дело в том, что физическое удаление любых записей в обросшей множеством прямых и косвенных связей БД очень трудоемкая задача (мягко выражаясь :-)).Итак, каждый объект должен иметь обязательные атрибуты OID, ClassId, и желательные – Name, Description, creation_date, change_date, owner. Разумеется, при разработке конкретной прикладной системы всегда можно добавить дополнительные атрибуты, характерные именно для данной задачи. Но не будем забегать вперед, эта тема описана чуть дальше.
Таблица OBJECTS
Изложенные соображения приводят нас к выводу, что, независимо от конкретного способа хранения остальных атрибутов объектов разных типов, вышеперечисленные атрибуты проще всего хранить в одной таблице. Можно, конечно, для каждого типа поддерживать набор этих фиксированных атрибутов отдельно, но зачем? Это не будет дублированием информации, но это будет дублированием сущностей. К тому же, единая таблица дает нам возможность иметь центральную точку входа для поиска любого объекта, что также является одним из важнейших преимуществ описываемой структуры.Так нарисуем же эту таблицу:
create domain TOID as integer not null;
create table OBJECTS(
OID TOID primary key,
ClassId TOID,
Name varchar(32),
Description varchar(128),
Deleted smallint,
Creation_date timestamp default 'now',
Change_date timestamp default 'now',
Owner TOID);
create table OBJECTS(
OID TOID primary key,
ClassId TOID,
Name varchar(32),
Description varchar(128),
Deleted smallint,
Creation_date timestamp default 'now',
Change_date timestamp default 'now',
Owner TOID);
В третьем диалекте вместо 'now' рекомендуется использовать CURRENT_TIMESTAMP (вместо 'today' – current_date и так далее).
Атрибут ClassId (идентификатор типа объекта) ссылается на таблицу OBJECTS, то есть описание типа также есть объект некоторого типа, имеющего, например, well-known ClassId = –100 (Где-то нужно добавить описание понятия well-known OID’s). Тогда список всех типов persistent объектов, известных системе, выбирается запросом select OID, Name, Description from OBJECTS where ClassId = -100)
Каждый объект, хранящийся в нашей БД, будет иметь одну (и только одну) запись в таблице OBJECTS, ссылающуюся на него, и, автоматически, набор соответствующих атрибутов. Благодаря этому, где бы мы ни встретили ссылку на некий неизвестный объект, мы можем просто и стандартным способом выяснить, что это за объект. Кстати, зачастую об объекте требуется лишь самая базовая информация – например, как в lookup combobox или многих реляционных соединениях (joins), – некое наименование, соответствующее ссылке. В этом случае нам вообще ничего не требуется, кроме таблицы OBJECTS и стандартного способа получения имени объекта по ссылке на него ("вот тебе и вторая выгода"). Существуют также типы – например, простейшие справочники, – которые не имеют других атрибутов, кроме уже имеющихся в OBJECTS – как правило, это краткое (код) и полное наименование, которые можно с успехом поместить в поля Name и Description таблицы OBJECTS. Вспомните, сколько таких справочников в вашей бухгалтерской системе – скорее всего, не меньше половины. Вот, считайте, эту половину справочников мы уже почти реализовали ("вот тебе и третья выгода!") – ибо кто сказал, что разные справочники (сущности) обязаны лежать в разных таблицах (отношениях), даже если они имеют одинаковые атрибуты? Ну и что, что так учили в институте? :-)
Простой плоский справочник можно получить из таблицы OBJECTS запросом
select OID, Name, Description
from OBJECTS
where ClassId = :LookupId
если известен ClassId элементов справочника. Если же известно только наименование типа, то чуть сложнее:
from OBJECTS
where ClassId = :LookupId
select OID, Name, Description
from OBJECTS
where ClassId = (select OID from OBJECTS where ClassId = -100
and Name = :LookupName)
from OBJECTS
where ClassId = (select OID from OBJECTS where ClassId = -100
and Name = :LookupName)
Чуть позже я покажу, как сделать такие простые справочники все же чуть более интеллектуальными :-).
Хранение более сложных объектов
К сожалению, реальные базы данных содержат и более сложные объекты, чем те, что могут целиком поместиться в таблицу OBJECTS. Способ их хранения безусловно зависит от предметной области и от внутренней организации объекта. Опишем три довольно широко известных варианта.Вариант 1. Объекты хранятся как в стандартной реляционной БД – атрибуты типа отображаются на атрибуты таблицы. Например, объекты-документы типа Order (заказ) с атрибутами "номер заказа", "комментарий", "заказчик" и "сумма заказа" хранятся в таблице
create table Orders (
OID TOID primary key,
customer TOID,
sum_total NUMERIC(15,2)),
связанной отношением 1:1 с таблицей OBJECTS по полю OID. Атрибуты "номер заказа" и "комментарий" хранятся в полях Name и Description таблицы OBJECTS. Orders также ссылается на OBJECTS через поле customer – так как заказчик наверняка также является объектом – например, частью справочника "Контрагенты". Все атрибуты объекта типа Order выдергиваются одним запросом
OID TOID primary key,
customer TOID,
sum_total NUMERIC(15,2)),
select o.OID,
o.Name as Number,
o.Description as Comment,
ord.customer,
ord.sum_total
from Objects o, Orders ord
where o.OID = ord.OID and ord.OID = :id
o.Name as Number,
o.Description as Comment,
ord.customer,
ord.sum_total
from Objects o, Orders ord
where o.OID = ord.OID and ord.OID = :id
То есть, все просто, понятно и привычно. Можно даже сделать view, и тогда будет все совсем как всегда :-).
Если у документа есть табличная часть (а у документа-заказа она, конечно, есть), то для нее создается дополнительная таблица, например, order_lines, как обычно связанная с Orders соотношением 1:M, в которую и помещается строчная часть.
create table order_lines (
id integer not null primary key,
object_id TOID, /* reference to order object – 1:M relation */
item_id TOID, /* reference to ordered item */
amount numeric(15,4),
cost numeric(15,4),
sum numeric(15,4) computed by (amount*cost))
id integer not null primary key,
object_id TOID, /* reference to order object – 1:M relation */
item_id TOID, /* reference to ordered item */
amount numeric(15,4),
cost numeric(15,4),
sum numeric(15,4) computed by (amount*cost))
Очень важное преимущество этого способа хранения – возможность работать с наборами объектов как с обычными реляционными таблицами, которыми они, собственно, и являются. То есть сохраняются преимущества реляционного подхода. Недостатки – не совсем тривиальна система сохранения и загрузки объектов, есть сложности с организацией наследования типов. Этот способ достаточно детально описан в [1] и [3], там же рассмотрены способы реализации в БД наследования типов.
Вариант 2. (См. [5]) Все атрибуты объекта любого типа хранятся в виде набора записей в единой таблице. В простейшем случае она выглядит примерно так
create table attributes (
OID TOID, /* ссылка на объект-владелец данного атрибута */
attribute_id integer not null,
value varchar(256),
constraint attributes_pk primary key (OID, attribute_id));
связанной 1:M с OBJECTS по OID. Также существует таблица
OID TOID, /* ссылка на объект-владелец данного атрибута */
attribute_id integer not null,
value varchar(256),
constraint attributes_pk primary key (OID, attribute_id));
create table class_attributes (
OID TOID, /*здесь ссылка на объект–описание типа */
attribute_id integer not null,
attribute_name varchar(32),
attribute_typeinteger,
constraint class_attributes_pk primary key (OID,attribute_id))
описывающая набор атрибутов (их имена и типы) для каждого объектного типа.OID TOID, /*здесь ссылка на объект–описание типа */
attribute_id integer not null,
attribute_name varchar(32),
attribute_typeinteger,
constraint class_attributes_pk primary key (OID,attribute_id))
Все атрибуты объекта выбираются запросом
select attribute_id, value
from attributes
where OID = :oid
или, с именами атрибутов,
from attributes
where OID = :oid
select a.attribute_id, ca.attribute_name a.value
from attributes a, class_attributes ca, objects o
where a.OID = :oid and
a.OID = o.OID and
o.ClassId = ca.OID and
a.attribute_id = ca.attribute_id
from attributes a, class_attributes ca, objects o
where a.OID = :oid and
a.OID = o.OID and
o.ClassId = ca.OID and
a.attribute_id = ca.attribute_id
В рамках этого варианта возможно также эмулировать реляционный стандарт. То есть, вместо выборки атрибутов объекта в нескольких записях (по атрибуту на запись) можно сделать эту выборку и одной записью – через join или подзапрос.
select o.OID,
o.Name as Number,
o.Description as Comment,
a1.value as customer,
a2.value as sum_total
from OBJECTS o
left join attributes a1 on a1.OID = o.OID and
a1.attribute_id = 1
left join attributes a2 on a2.OID = o.OID and
a2.attribute_id = 2
where o.OID = :id;
o.Name as Number,
o.Description as Comment,
a1.value as customer,
a2.value as sum_total
from OBJECTS o
left join attributes a1 on a1.OID = o.OID and
a1.attribute_id = 1
left join attributes a2 on a2.OID = o.OID and
a2.attribute_id = 2
where o.OID = :id;
Нетрудно видеть, что с ростом количества атрибутов скорость такой выборки линейно падает, потому что на каждый атрибут требуется еще один join.
Возвращаясь к примеру с документом Order, получим, что атрибуты "номер заказа" и "комментарий" по-прежнему хранятся в таблице OBJECTS, а "заказчик" и "сумма заказа" – в двух разных записях таблицы attributes. (Тут нужно больше и подробнее). Этот подход подробно описан в статье Анатолия Тенцера [5]. Его преимущества немаловажны – стандартизованный способ выборки и сохранения атрибутов объекта, простота расширения и изменения типа, простота реализации наследования объектов, абсолютно элементарное устройство БД (что весьма немаловажно), потому что сколько бы ни хранилось различных типов объектов в БД, количество таблиц не растет – как было четыре-пять-десять, так и останется. Недостаток – плохо соответствует стандартной реляционной модели, соответственно неприменимы многие приемы, стандартные для реляционных БД. Выборка атрибутов конкретного объекта существенно замедлена (по сравнению с предыдущим вариантом) и падает с ростом количества атрибутов объекта. Затруднена работа с объектами средствами БД. Возможна также некоторая избыточность данных, поскольку вместо одного поля объекта хранится целых три поля – OID, attribute_id, value.
Вариант 3. Все хранится в BLOB, с применением одного из готовых форматов хранения (persistent format), например, dfm (VCL streaming) из Borland VCL, XML, или изобретением своего собственного. Пояснять тут особо нечего. Преимущества очевидны – загрузка данных из БД элементарна и быстра, не требуются никакие доп. структуры БД, возможно хранение произвольных объектов, в том числе неструктурированных, таких как документы Word, HTML страницы и т. д. Недостаток также очевиден – никакой реляционностью тут не пахнет, и всю обработку придется выполнять вне БД, используя БД только как хранилище объектов.
Выводы сделать несложно – да они и так всем известны :-). Все три варианта безусловно полезны и имеют право на жизнь – причем зачастую имеет смысл применять все три одновременно. Просто при выборе варианта следует иметь в виду перечисленные преимущества и недостатки каждого. Если присутствует (или возможно ее добавление в будущем) массированная реляционная обработка с использованием некоторого атрибута объекта, то его лучше всего хранить с применением варианта 1 – как наиболее приближенного к стандартному реляционному способу. Если такая обработка несложна или наборы данных невелики или очень важна простота организации БД, то имеет смысл применять вариант 2. Если же БД служит только как хранилище объектов, и вся работа с ними происходит только в run-time представлениях, а не в БД (за исключением, быть может, работы с атрибутами, хранящимися в таблице OBJECTS) – тут трудно составить конкуренцию варианту 3, как простейшему в реализации и быстрому в работе.
Связи между объектами
(См. также [5], раздел "Связи")Связи – атрибуты объектов
При традиционном подходе к проектированию реляционных БД, на мой взгляд, также существуют некоторые проблемы с установлением связей между отношениями.- Реляционная связь слабо или совсем не документирована "сама-в-себе" – то есть если не существует FK, то без проектной документации невозможно догадаться о самом существовании связи (Тут конечно можно поспорить, сказав, что если нет FK, то нет и реляционной связи. Но мне это кажется не совсем справедливым, ибо связь – это все же нечто куда большее, чем просто FK. FK же – это не более, чем constraint). Если же FK существует, то существование связи видимо, но далеко не всегда понятна ее сущность – разве что очень хорошо подобраны имена атрибутов и имя FK. А, как известно, самодокументируемость есть одна из существенных характеристик хорошего стиля программирования.
- Для раскрытия связи (то есть для доступа к кортежу из некоторого отношения по ссылке на него) для каждой связи необходимо иметь свой, специфичный именно для этой связи, метод раскрытия. В обычной объектной модели связь – это когда поле одного объекта содержит указатель (ссылку) на другой объект. Если, например, все классы некоей системы унаследованы от класса MyObject, который имеет свойство Name, (либо реализуют один известный интерфейс, либо язык поддерживает RTTI, и т.д), мы по ссылке на неизвестный объект можем, используя объектный полиморфизм, выяснить как минимум Name, а в случае поддержки RTTI – и все остальное о конкретном объекте. И все это мы можем выяснить, не имея ничего, кроме ссылки. Что нам в этом случае предлагает реляционная модель?
Для примера возьмем тот же документ – заказ. В нем одно из полей – ссылка на заказчика. Как, при стандартном способе проектирования, для отдельно взятого заказа выяснить самый часто используемый атрибут – наименование заказчика? Для этого нужно знать, где и как хранится список заказчиков, знать, как устроена связь между заказом и заказчиком, знать, наконец, что связь вообще существует :-), и, совсем наконец, уметь построить некое выражение, раскрывающее связь – например, реляционный join или вызов хранимой процедуры, или что там еще бывает на свете. Такие вещи обычно hardcoded в каждом конкретном случае – то есть связь определяется на этапе проектирования и программирования некоторой сущности посредством FK, а также записанных где-то SQL-выражений для выборки и сохранения объекта (или привязки lookup-control к полю recordset’а – что совсем плохо). Еще ярче эта проблема проявляется в другом примере – когда неизвестно заранее, куда ведет ссылка. Представим себе систему учета чего-нибудь, базирующуюся на проводках. Проводки лежат в отдельной таблице, одной проводке соответствует одна запись. Каждая проводка имеет атрибут “количество” (денег, товаров, и т.д.) и несколько аналитических признаков – или, как сейчас все привыкли говорить благодаря 1С, субконто. Каждый признак – это поле-ссылка на некоторый справочник, причем что за справочник – на этапе проектирования и программирования не известно, и зависит от некоторых дополнительных условий, возникающих уже только в run-time (например, если речь идет об 1С бухгалтерии, от счета проводки – потому что именно он в 1С определяет набор аналитических признаков). Как же быть в этом случае (стандартный FK тут сделать не удастся)? Как по ссылке из проводки определить наименование объекта, на которое проводка ссылается? Можно – но опять же это определено на этапе проектирования. Определено это может быть следующим образом: нужно залезть в описание счета, посмотреть в нем, какой именно тип объекта аналитического учета живет в этом поле проводки, затем найти, в какой таблице живет этот тип объекта, и наконец найти, как в этой таблице называется поле, в котором хранится наименование объекта. Что касается самодокументируемости связи – в данном случае она присутствует (есть описание набора субконто в параметрах счета), Плохо, что присутствует она в слишком проблемно-ориентированном виде. Ведь в той же БД, где у нас ведутся эти самые проводки, есть и другие связи – с ними-то как быть? Как всегда – то есть никак. Что в select’е напишем – так оно и свяжется…
Первые две проблемы имеют простое решение – если и не полное, то, во всяком случае, простое и удобное. Все ссылки на объекты делаются только через таблицу OBJECTS и имеют тип TOID. В самом деле, если каждый объект имеет в OBJECTS соответствующую ему запись, то почему нет? Далее, в таблице Classes для каждого атрибута, имеющего тип “ссылка”, должно существовать некоторое описание правил, ограничивающих множество объектов, на которые можно ссылаться. Например, “только на объекты перечисленных типов”, или “только на объекты из некоторой папки”.
- Такая ссылка лучше документирована, поскольку только по самой ссылке (значению типа OID) можно сразу выяснить тип объекта, на который ссылаются, обратившись к OBJECTS.
ClassId типа, если известна ссылка id на объект:
select ClassId
from OBJECTS
where OID = :id
from OBJECTS
where OID = :id
Имя типа:
select o.ClassId, o1.name as ClassName
from OBJECTS o, OBJECTS o1
where o.ClassId = o1.OID and OID = :id
from OBJECTS o, OBJECTS o1
where o.ClassId = o1.OID and OID = :id
- Для раскрытия ссылки опять же достаточно тривиального запроса и значения ссылки:
select o.Name, o.Description, o.ClassId
from OBJECTS o
where o.OID = :id
from OBJECTS o
where o.OID = :id
Если же ссылка еще не создана (например, пользователь как раз создает новый объект и должен ввести ссылку), то правила ее создания единым образом извлекаются из Classes.
Внешние связи между объектами
(См. [5], раздел "Связи")Предыдущий раздел описывал случаи, когда связь (ссылка) есть атрибут объекта. Однако есть связи, которые, в общем случае, частью объектов не являются.
- Связь типа "кто кого породил". Пример: некий документ порождает целую цепочку действий и документов, вместе образующих некий бизнес-процесс. Однако те же самые документы и действия встречаются и в совершенно других бизнес-процессах, а также как самостоятельные единицы. В этом случае нет смысла в каждом объекте делать поле-ссылку на породивший объект – во-первых, они могут быть разных типов, во-вторых, их может быть несколько.
- Чисто логическое вхождение чего-то куда-то. Пример: файлы входят в каталоги, но тем не менее являются вполне самостоятельными объектами и не меняют (как правило) свой смысл от смены каталога.
- И другие :-)
Эта задача решается введением дополнительной таблицы – таблицы связей.
create table links(
link_type TOID,
left TOID,
right TOID,
Constraint LINKS_PK primary key (link_type, left, right))
link_type TOID,
left TOID,
right TOID,
Constraint LINKS_PK primary key (link_type, left, right))
Это почти обычная таблица для организации связи M:M. Left и right – это ссылки на левую и правую стороны связи, то есть на два объекта, между которыми установлена связь. Почти обычная – потому что разница все же есть. Во первых, у нас имеется единое множество объектов всех типов и единый способ ссылаться на них (таблица OBJECTS и система уникальных ключей). Во вторых, есть еще поле link_type. Первое дает нам возможность использовать таблицу links для любых внешних связей между любыми объектами, в отличие от стандартного реляционного подхода, где для реализации каждой связи M:M необходимо создавать отдельную таблицу, потому что типы ключей не стандартизированы, а если и стандартизированы (например только integer), то их значения уникальны только в пределах таблиц. А второе (поле link_type) дает возможность определять тип связи и правила ее создания.
Что все это означает для нас? Возьмем известный вариант реализации древовидной структуры в реляционной таблице – id, parent_id, описанный, например, в [6]. Используя таблицы Objects и links, легко можно получить эту структуру следующим запросом (для некоторого конкретного типа связи):
select o.OID as id,
l.left as parent_id,
o.name,
o.description
from objects o, links l
where o.OID = l.right and l.link_type = :link_type
l.left as parent_id,
o.name,
o.description
from objects o, links l
where o.OID = l.right and l.link_type = :link_type
Такая структура полезна, проста, и к тому же имеется множество визуальных компонентов, реализующих древовидное представление визуально.
Однако часто бывает необходимо организовать более сложную систему связей между объектами. Так вот, таблица links – вот тут начинается самое вкусное :-) – дает нам возможность создавать деревья и сети объектов почти неограниченной сложности. Зачем? Чтобы пояснить, рассмотрим пример. Возьмем снова наш объект order. Пусть,
- Во-первых, для организации некоего глобального логического каталога объектов в БД желательно, чтобы все объекты типа order лежали одновременно
- в папке Orders – Заказы.
- в папке менеджера, который его создал и ведет связанный с ним бизнес-процесс.
- в папке всех документов компании за текущий месяц.
- в личной папке клерка, отвечающего за этот конкретный заказ.
- еще где-нибудь.
- Во-вторых, пусть мы хотим видеть в виде графа и обрабатывать как единое целое весь бизнес-процесс (БП), частью которого является наш order. Пусть, например,
- БП начался с договора заказчика и поставщика о постоянном обслуживании сроком на год.
- Следствием этого стало создание документа “график поставок”.
- Затем, согласно этому договору и графику, появляется наш order,
- затем invoice, затем отгрузка, и т. д.
Теперь опишем решение этих (как мне кажется, довольно распространенных, по крайней мере, в системах, связанных с документооборотом) задач.
Глобальный каталог объектов
Первая задача решается немедленно в лоб, поскольку в отличие от структуры id, parent_id наша структура позволяет иметь неограниченное количество ссылок на один и тот же объект – благодаря тому, что понятие объекта и связи разделены логически и физически (объекты в objects, связи – в links). Введем тип folder – “логическая папка” с ClassId = 100; пусть также тип order имеет ClassId = 200. Тогда набор записей в нашей структуре, реализующий условия задачи (правда без записей в таблице Classes), будет:Objects
| OID | Name | Description | ClassId |
|---|---|---|---|
| 0 | Root | Корневая папка | 100 |
| 1000 | ЛичныеПапки | Личные папки сотрудников | 100 |
| 1001 | Документы | Все документы компании | 100 |
| 1002 | Заказы | Все заказы клиентов | 100 |
| 1003 | Иванов | Личная папка менеджера Иванова | 100 |
| 1004 | Февраль2002 | Все документы за февраль 2002 года | 100 |
| 1005 | Март2002 | Все документы за март 2002 года | 100 |
| 1006 | Сидоров | Личная папка клерка Сидорова | 100 |
| 1007 | ЕщеОднаПапка | Папка просто так | 100 |
| 2001 | Заказ0001 | Наш заказ | 200 |
| Link_type | Left | Right | Содержание связи |
|---|---|---|---|
| 0 | 0 | 1000 | Папка ЛичныеПапки входит в root |
| 0 | 0 | 1001 | Папка Документы входит в root |
| 0 | 0 | 1007 | Папка ЕщеОднаПапка входит в root |
| 0 | 1000 | 1003 | Папка Иванов входит в ЛичныеПапки |
| 0 | 1000 | 1006 | Папка Сидоров входит в ЛичныеПапки |
| 0 | 1001 | 1004 | Папка Февраль2002 входит в Документы |
| 0 | 1001 | 1005 | Папка Март2002 входит в Документы |
| 0 | 1001 | 1002 | Папка Заказы входит в Документы |
| 0 | 1003 | 2001 | Заказ0001 входит в личную папку Иванова |
| 0 | 1006 | 2001 | Заказ0001 входит в личную папку Сидорова |
| 0 | 1005 | 2001 | Заказ0001 входит в папку Март2002 |
| 0 | 1002 | 2001 | Заказ0001 входит в папку Заказы |
select o.*
from objects o, links l
where l.link_type = 0 and
o.OID = l.right and
l.left = :folder_id
from objects o, links l
where l.link_type = 0 and
o.OID = l.right and
l.left = :folder_id
А вся древовидная структура целиком выглядит примерно так:
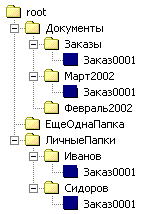
При этом объект "Заказ0001" присутствует в таблице Objects в единственном числе, а ссылки на него есть в нескольких папках.
Более умный простой справочник – иерархический
В самом начале статьи я обещал рассмотреть способ построения более интеллектуального справочника, чем простейшего, получаемого из OBJECTS запросом типаselect OID, Name, Description
from OBJECTS
where ClassId = :LookupId
результатом которого будут все объекты определенного типа из таблицы OBJECTS. Слегка изменив этот запрос и считая по-прежнему, что ClassID папки равен 100, а тип связи (link_type) "логическое вхождение" равен 0, напишем
from OBJECTS
where ClassId = :LookupId
select o.OID, o.Name, o.Description
from OBJECTS o
inner join Links l on l.right = o.OID and
l.link_type = 0
l.left = :LookupRoot and
where o.ClassId = :LookupClassId or
o.ClassId = 100
from OBJECTS o
inner join Links l on l.right = o.OID and
l.link_type = 0
l.left = :LookupRoot and
where o.ClassId = :LookupClassId or
o.ClassId = 100
Этот запрос вернет нам первый уровень иерархического справочника, начинающегося с папки с OID LookupRoot, и содержащего все нижележащие объекты (в иерархии каталога) с ClassId = LookupClassId. Запрос, раскрывающий любую папку первого уровня, будет выглядеть точно также, только вместо LookupRoot потребуется задать OID этой папки. Показать результат этого запроса пользователю в диалоговом окне и в привычном ему виде – с папками, раскрывающимися по двойному клику, и объектами внутри этих папок, которые можно выбрать – уже дело техники. Например, этот диалог может быть точно таким же, как стандартный диалог системы “Открыть файл”. При этом, реализовав этот диалог и управляющий им run-time объект (у себя я называю его DirectoryBrowser), мы получим универсальный пользовательский и программный интерфейс для большинства справочников в системе.
На самом деле не только справочников. Фактически мы получим универсальный API и пользовательский интерфейс для просмотра каталога любых объектов нашей БД, примерно аналогичный по функциям связке Windows Shell API (IShellFolder, IShellBrowser и т. д.) и Windows Explorer. Можно даже сильно постараться и встроить свои механизмы в сам Windows Explorer – тогда объекты БД станут доступны из обычного окна проводника. Не будем тыкать пальцами, но мы знаем кто это делал и даже сделал! :-)
Новый тип справочника можно будет создать в два взмаха мышью, задав для него LookupRoot и LookupClassId (возможно, несколько ClassId’ов – если справочник может содержать несколько типов. Например, справочник контрагентов может содержать поставщиков и покупателей, которые, в свою очередь, могут образовывать отдельные справочники).
О способе создания справочников, требующих для выбора искомого объекта дополнительных полей, помимо содержащихся в Objects, я расскажу позже, в разделе о реализации библиотеки доступа к нашей БД.
Путевое имя в каталоге
Раз уж мы можем построить в нашей БД структуру типа каталога, то грех не использовать другую старую добрую абстракцию – доступ к объектам этого каталога через путевое имя. Например, для нашего примера путь в объекту Заказ0001 (точнее, один из возможных путей) можно записать как /Документы/Заказы/Заказ0001 или /ЛичныеПапки/Иванов/Заказ0001. В самом деле, путь в каталоге до некоторого объекта, построенный, начиная от некоторого известного узла каталога (root или другого), однозначно идентифицирует объект при условии, что мы обеспечили уникальность имен объектов в пределах каталога. "Однозначно идентифицировать объект по пути" в нашем случае означает, что по такому пути можно найти OID объекта. При этом путей к одному и тому же объекту может быть много (поскольку ссылок на объект может быть сколько угодно), и каждый из них указывает на один и только один объект. Уникальность имен в пределах каталога можно обеспечить, наложив при помощи триггера на таблицу Links ограничение, срабатывающее на тип связи link_type = 0.Известную проблему, связанную с невозможностью полностью поддерживать такого рода ограничения с помощью триггера, мы тут обсуждать не будем – тем более что в данном случае ее можно обойти. :-)
Прелести использования путевых имен вместо OID (а точнее, вместе с ним) подробно расписывать не обязательно. Их много и они очевидны.
Нахождение OID объекта по пути легко реализовать в хранимой процедуре БД, что даст возможность использовать путевые имена в запросах и других хранимых процедурах и триггерах, повышая таким образом логичность и связность БД. Для реализации такой процедуры в Interbase придется еще написать простейшую UDF для разбора строки пути, для MS SQL достаточно возможностей TransactSQL.
Другие типы связей
Используя возможности, предоставляемые таблицей Links, можно построить множество полезных структур, объединяющих объекты нашей БД, помимо только что описанного глобального логического каталога. Например, можно решить задачу с организацией связного бизнес-процесса (БП), описанную в конце предыдущего раздела. Тип объекта, определяющий некоторый тип БП (например, уже описанное долгосрочное обслуживание), в этом случае представляет собой набор возможных связей между типами документов, которые можно создать в его контексте. Объект, описывающий конкретный БП (договор на обслуживание номер 10), содержит набор уже существующих связей между уже созданными документами, предоставляет интерфейсы для создания последующих документов в цепочке БП, а также является центральным звеном при построении визуального представления цепочки (в общем случае сети) документов и объектов – частей данного БП. В этом случае нам понадобится новый тип связей (link_type), со своими правилами создания и ограничениями, например, link_type = 1.И так далее. Каждый может придумать для себя сам полезные ему типы. Могу предложить следующие: еще один тип для представления иерархии классов, и еще один – для иерархии счетов из плана счетов бухучета и некоторых других справочников.
Таблицу Links можно также использовать для связей типа master-detail, если detail-набор есть список объектов. Пример: табличной частью банковской выписки является набор платежных документов. Преимущество использования для таких отношений связей через таблицу Links является то, что не требуется в тысячный раз реализовывать полный набор функций и полей (master_id и т. д.) для очередной master-detail связи. Вместо этого используется стандартный, уже реализованный и отлаженный способ связи…
Система ограничения доступа
Благодаря тому, что обращение ко всем объектам БД идет через таблицу Objects, можно также реализовать систему ограничения доступа на уровне документа, или записи – что является "вековой мечтой" многих программистов, занимающихся разработкой документно-ориентированных БД. Причем эта система будет независима от типов объектов – то есть при добавлении нового типа ее не придется менять. Здесь я очень кратко опишу два варианта – самый простой и быстрый, и более сложный и гибкий. Они не обеспечивают абсолютной защиты – то есть их можно обойти на уровне SQL, но возможно сделать так, чтобы пользы это принесло немного. Вообще говоря, эти способы обеспечивают скорее некоторое удобство для разработчика приложений – всегда можно быстро и однообразно выяснить, имеет ли пользователь некие права на некий объект – например, написав для этого простейшую функцию BOOL check_access(char* user, int object, int right) или что-то в этом духе.Итак:
1) Создается стандартная структура поддержки списка пользователей и групп:
create table users (
UID integer not null primary key,
name varchar(32) unique);
create table groups (
UID integer not null primary key,
name varchar(32) unique);
/* уникальность имен пользователей и групп - по вкусу */
create table users_groups(
UID integer not null,
GID integer not null,
constraint users_groups_pk primary key (UID, GID));
create procedure uid_by_name(name varchar(32))
returns (uid integer)
as
begin
select uid from users where name = :name into :uid;
end
UID integer not null primary key,
name varchar(32) unique);
create table groups (
UID integer not null primary key,
name varchar(32) unique);
/* уникальность имен пользователей и групп - по вкусу */
create table users_groups(
UID integer not null,
GID integer not null,
constraint users_groups_pk primary key (UID, GID));
create procedure uid_by_name(name varchar(32))
returns (uid integer)
as
begin
select uid from users where name = :name into :uid;
end
В таблицу Objects добавляется два поля – read_group integer, write_group integer – ссылки на таблицу groups.
Создается представление
create view s_objects as
select o.*
from objects o, users_groups ug
where (o.read_group = ug.gid and
ug.uid = uid_by_name(CURRENT_USER));
grant select on s_objects to public;
select o.*
from objects o, users_groups ug
where (o.read_group = ug.gid and
ug.uid = uid_by_name(CURRENT_USER));
grant select on s_objects to public;
Доступ к Objects закрывается для всех, кроме представления s_objects. Это представление обеспечивает для пользователя реализацию права на чтение всех объектов, для которых текущий пользователь входит в группу read_group данного объекта. Для таблицы objects создаются триггеры before insert, before delete, before update, проверяющие права доступа к объекту на основании CURRENT_USER и write_group. Исходный текст триггеров тривиален, и здесь не приводится. Также придется сделать триггеры before update для каждой таблицы, содержащей доп. атрибуты объектов. Эти триггеры будут совершенно одинаковыми. Триггер before update должнен всего лишь выполнять update поля objects.change_date, вызывая таким образом проверку прав доступа триггером objects before update.
2) Суть второго варианта примерно такая же, но строится он базе известного алгоритма ACL – access control list, в котором для каждого объекта можно задать целый список разнообразных прав доступа для разных пользователей, и который применяется во многих многопользовательских файловых системах. Итак, вместо полей read_group и write_group создается дополнительная таблица:
create table ACL( id integer not null primary key,
acl_id integer not null, /*номер acl*/
uid integer not null, /*ссылка на пользователя*/
right integer not null /*идентификатор конкретного права доступа*/
))
а в таблицу Objects добавляется одно поле – acl_id integer not null, являющееся ссылкой на acl.acl_id. Запрос
acl_id integer not null, /*номер acl*/
uid integer not null, /*ссылка на пользователя*/
right integer not null /*идентификатор конкретного права доступа*/
))
select a.uid, a.right
from acl a, objects o
where acl_id = o.acl_id and o.OID = :oid
from acl a, objects o
where acl_id = o.acl_id and o.OID = :oid
вернет нам ACL (список прав доступа) для любого объекта из objects. Количество самих списков может быть значительно меньше, чем объектов – благодаря тому, что несколько объектов могут разделять один список, как это и реализовано в файловых системах, например в NTFS. Сам контроль доступа выполняется примерно так же, как в первом варианте, за исключением того, что представление s_objects и триггера проверки прав становятся сложнее и медленнее. Определение представления s_objects я приводить не буду, потому что оно хотя и не сложно, но зависит от определенного в конкретной системе набора прав доступа, и поэтому является проблемно-зависимым.
Преимущества и недостатки. Преимуществами первого варианта являются простота реализации и скорость работы реляционных выборок с участием s_objects – так как s_objects является простым соединением и скорость выборки из него ненамного меньше, чем напрямую из objects. Недостатком является малая гибкость – далеко не всегда достаточно возможностей, предоставляемых этим вариантом. Второй вариант значительно гибче, но сложнее в реализации, и использование его в реляционных выборках с участием s_objects, возможно, будет затруднено из-за более медленной процедуры проверки прав на чтение. Наконец, общими недостатками обоих вариантов являются:
- необходимость создания триггеров на каждую новую таблицу хранения доп. атрибутов
- оба варианта никак не обеспечивают защиты от чтения дополнительных таблиц атрибутов объектов, если такое чтение производится в обход s_objects. Однако можно предпринять некоторые дополнительные действия, чтобы прямое чтение таблиц атрибутов приносило мало пользы злоумышленнику. Например, хранить в objects один-два существенных атрибута, без которых большинство объектов практически не имеют смысла.
Вариант реализации клиентской или middle tier библиотеки доступа
Sorry, under constructionЛитература
- Mapping Objects To Relational Databases – White Paper. Scott W. Ambler. 26-FEB-1999
- Описание системы Ultima-S. Владимир Иванов.
- The Design of a Robust Persistence Layer For Relational Databases. Scott W. Ambler. 28-NOV-2000
- Естественные ключи против искусственных ключей. Анатолий Тенцер. 20 июля 1999.
- База данных – хранилище объектов. Анатолий Тенцер.
- Древовидные (иерархические) структуры данных в реляционных базах данных. Дмитрий Кузьменко, iBase. А также другие статьи о деревьях и объектах на www.ibase.ru/develop/.