 En
EnДревовидные (иерархические) структуры данных в реляционных базах данных, часть 2
Кузьменко Дмитрий, iBase.ru, обновления – 02.04.2004.

Некоторые комментарии по поводу первой части статьи
Много времени прошло с момента опубликования первой части статьи, а ситуация в этой области никак не изменилась. Я получил много писем с просьбой продолжения, два полезных комментария, которые можно считать дополнением к этой статье (RegistryLINK в базе данных и комментарийLINK), и несколько писем с указанием на ошибки в коде первой части статьи. Кроме этого вышла отличная статья Владимира Котляревского по реализации ООП в РСУБДLINK.Ошибки я исправлять не буду, пусть остается как есть. Тем более что код (по крайней мере Pascal), приведен из тестового примера, который уже давно удален. К этой части статьи приложен архив, в котором есть и пример на Delphi и база данных, так что реально работающий код берите оттуда.
Единственным пока заслуживающим внимания замечанием к первой части статьи является уточнение по поводу вторичного ключа, создаваемого по полю PARENT. Здесь возможно два варианта:
- Убрать в объявлении столбца OBJECTS.PARENT ограничение NOT NULL, и построить Foreign Key как ссылка с PARENT на ID этой же таблицы. Корневые элементы тогда будут иметь PARENT = null.
- Не создавать FK, создать индекс по PARENT вручную, для корневых элементов устанавливать PARENT = 0. При этом контролировать ссылку PARENT на существующего родителя (ID) придется в приложении (или триггерами).
Так что при реализации вам придется ориентироваться на тот вариант, который вам просто больше нравится.
Не советую также создавать корневой элемен со ссылкой "в никуда", и только потом накладывать ограничение FOREIGN KEY. В результате restore такой базы данных будет невозможен, понятно почему. На этом давайте с первой частью закончим, и перейдем ко второй.
"Один ребенок у двух родителей" или использование ссылок
В рассмотренном в первой части статье способе хранения информации о "родословной" объектов есть существенный пробел. Если говорить о наследовании в смысле родителей и детей, то наша структура БД такого не позволяет. Т. е. у родителя может быть несколько детей, но двух родителей у одного объекта быть не может – родитель объекта однозначно определяется полем PARENT.Разумеется, если бы нам потребовалось хранить в базе данных генеалогическую информацию, то мы сделали бы совершенно другую структуру БД. Просто завели бы список "людей" и во второй таблице организовали между ними "родственные отношения".
У нас модель данных несколько другая. И реализация "множественного родительства" тоже будет, но иная.
Насколько мне известно, популярной литературы по рассматриваемому вопросу не существует. Поэтому и предлагаемая реализация – частная. Почему я завел об этом речь? Дело в том, что достаточно интересная реализация связей между объектами реальной системы существует в файловых системах OS/2 и UNIX. В OS/2 – Shadow, в UNIX – HARDLINK и SOFTLINK. Именно эти реализации мы и попытаемся применить к нашей базе данных.
Добавим к нашей таблице OBJECTS поле REALID:
ALTER TABLE OBJECTS ADD REALID INTEGER NOT NULL DEFAULT -1
Лично я не люблю связываться со значением NULL, когда речь идет о ссылках. Это касается и поля PARENT. Значение -1 в поле REALID будет означать, что эта запись представляет реальный объект. А любое, которое > 0 (т. е. равно какому-то существующему ID) будет означать, что запись представляет собой ссылку на реальный объект. Причем такой вариант ссылок реализует SOFTLINK или Shadow OS/2.
Примечание. Чтобы не возбуждать повторно дискуссий о возможности null в foreign key, отошлю вас к Дейту. Конкретно к книге "Введение в системы баз данных". Таким образом, если вы хотите поспорить на эту тему – спорьте с Дейтом :-)
Правда, при однотипности "родителей" и "детей" в нашей БД не совсем ясно, как можно использовать подобные ссылки. Поэтому придется ввести разделение объектов, хранимых в таблице OBJECTS, на подтипы"Каталог" и "файл"
Действительно. А почему бы не имитировать хранение в базе данных каталогов и файлов? Ведь в основном информация, используемая в организациях, структурирована подобным образом. Файлы или документы – все хранится в каталогах или папках. Каталоги – в еще больших "шкафах" и т. д.В связи с этим придется добавить еще одно поле в таблице OBJECTS:
ALTER TABLE OBJECTS ADD ISNODE INTEGER
Поле ISNODE будет являться индикатором: если запись является "каталогом", то ISNODE=1. Если запись является "файлом", то ISNODE=0.
Уфф. Вот теперь можно продолжить про ссылки на реальные объекты. Пример из жизни – сотрудник работает в одной организации, и устроен на полставки в другую. Т. е. сам объект "сотрудник" один и тот же – с ФИО, паспортом и адресом, а работает в разных организациях. Наличие ссылок на объекты позволяет в каталоге первой организации создать объект "сотрудник", а в каталоге второй организации – ссылку на объект "сотрудник". Это нужно для того, чтобы иметь возможность модифицировать данные о сотруднике независимо от расположения ссылок.
Итак, данные представлены в виде:
| ID | PARENT | REALID | ISNODE | NAME |
|---|---|---|---|---|
| 1 | 0 | -1 | 1 | ACME Inc |
| 2 | 1 | -1 | 1 | Сотрудники |
| 3 | 2 | -1 | 0 | Иванов И.И. |
| 4 | 0 | -1 | 1 | Total Intl. |
| 5 | 4 | -1 | 1 | Полставочники |
| 6 | 5 | 3 | 0 | X |
ACME Inc.
Сотрудники
Иванов И.И.
Total Intl ^
Полставочники !
X-----------------!
Запись с ID=6 при помощи REALID ссылается на запись с ID=3. При этом совершенно неважно, какого типа эта запись (ISNODE) и какие у нее значения остальных полей (в нашем случае только NAME). Почему? Да потому, что когда мы возьмем запись ID=6, то увидев REALID>=0 должны тут же считать настоящую запись с ID=REALID и рассматривать в качестве данных только ее поля. Разумеется, в поля записи-ссылки можно (и нужно) занести информацию, идентичную реальной записи, с тем чтобы видеть содержимое нужных полей сразу при просмотре данных. Если такая запись содержит кроме текстовых и числовых полей еще и BLOB, то эти поля уже нет необходимости дублировать в записи-ссылке. Это существенно сэкономит дисковое пространство, занимаемое базой данных.Сотрудники
Иванов И.И.
Total Intl ^
Полставочники !
X-----------------!
Таким образом, мы теперь можем создавать ссылки как на "файлы", так и на целые "каталоги".
Примечание. Оригинальный id ссылки все-таки нужно "помнить" в приложении. Дело в том, что ссылки могут иметь другие имена (Name), в отличие от имен объектов. Например, как Shortcut-ы в Windows. Поэтому при обновлении "ссылки" нужно определять, что именно меняется – если имя, то его можно сменить у "ссылки", а если другие атрибуты, то их нужно менять у оригинальной записи.
Перенос элементов дерева
В первой части статьи, в самом последнем разделе ("Визуализация древовидной структуры") были приведены тексты триггеров, которые обеспечивают корректное, изменение количества подэлементов у конкретного узла. Давайте еще раз посмотрим на пример интерфейса такой программы: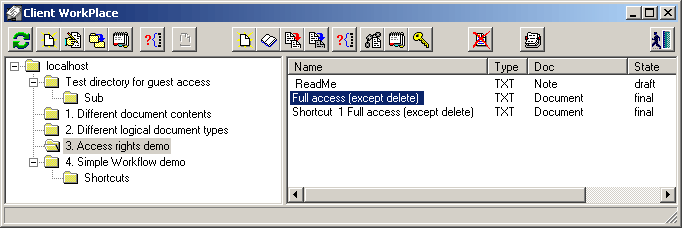
Например, нам требуется переместить папку Sub из одной папки в другую. То есть, папка Sub должна поменять идентификатор своего "родителя". Примерный запрос может выглядеть так:
UPDATE OBJECTS
SET PARENT_ID=:OWID
WHERE ID = :DID;
SET PARENT_ID=:OWID
WHERE ID = :DID;
Однако, элемент Sub является "конечным" в конкретной ветке "дерева", т. е. его можно перенести в любую другую папку. А что если попытаться перенести целиком вышестоящую папку? Тоже никаких проблем – все дочерние элементы автоматически "переместятся" вместе со своим родителем. Но вот что будет, если попытаться перенести папку "Test directory ..." в папку Sub?
Ничего хорошего, конечно, не получится. Даже если PARENT_ID проверяется на соответствие ID при помощи FK, зацикливание дерева FK проверить не сможет. Поэтому проверять такие ситуации нужно самостоятельно.
Надо сказать, что в конкретной реализации, которую вы видите на картинке, дерево объектов перерисовывается не из БД, а просто модифицируется при успешном выполнении любой операции (перенос, создание элемента и т. п.). Собственно, нет никакой необходимости перечитывать информацию, если операция по изменению дерева прошла в базе успешно. Возразить здесь можно, только если речь идет об узлах дерева, которые активно модифицируются в многопользовательской среде. Однако, такие операции относительно редки, не у всех пользователей могут быть права на выполнение таких действий, и, в конце концов, при операции перемещения элемента из базы данных (или промежуточного сервера) можно выдать событие, чтобы клиентские места перерисовали нужную ветку дерева или все дерево целиком (правда, тут надо предусмотреть последствия такой перерисовки, если пользователь в это время работает с деревом – часто компоненты или не делают expand для открытых узлов, или делают expand для всего отображаемого дерева).
Итак, как можно проверить зацикливание? Первый способ – прямо на клиенте, второй способ – в базе данных. Первый способ лучше, и вот почему: если визуальное отображение дерева написано с использованием TTreeView, то код проверки очень простой:
// DestNode, SourceNode = TTreeNode
// не пытаемся ли сделать "зацикливание" дерева
if DestNode.HasAsParent(SourceNode) then
begin
// нельзя перемещать или копировать объект сам в себя
MessageDlg('Can not move or copy folder into itself.', mtError, [mbCancel], 0);
Exit;
end;
// не пытаемся ли сделать "зацикливание" дерева
if DestNode.HasAsParent(SourceNode) then
begin
// нельзя перемещать или копировать объект сам в себя
MessageDlg('Can not move or copy folder into itself.', mtError, [mbCancel], 0);
Exit;
end;
При этом до обращения к базе данных дело даже не доходит. Если же проверять такую ситуацию в базе, то получается, что клиентская часть безусловно выдает команду вроде ChangeParent(Id, NewParent), после чего процедура или триггер должны будут проверить зацикливание например при помощи уже описанной ранее процедуры GETPARENTS или ее модификации, и в случае зацикливания выдать Exception. Т. е. мы явно обращаемся к БД, даже в случае неуспешного выполнения такой операции.
Разумеется, гарантии целостности данных в самой БД, без такого контроля, остаются под вопросом – программист может забыть делать проверку на зацикливание в приложении. Поэтому вы сами должны определиться, что для вас важнее – либо исключить лишние обращения к базе данных, либо максимально обезопасить данные в случае прямого их изменения. (Могу добавить, что никто не запрещает создать свой класс над TTreeView и внедрить туда метод перемещения элементов дерева, который сам будет контролировать зацикливание, т. е. защититься можно разными способами).
Обновление родителя
Этот вопрос вынесен как подзаголовок темы "Перемещение элементов", хотя он возникает при создании и удалении дочерних элементов (собственно, перемещение – это тоже "удаление" дочернего элемента и "создание" его в другом месте).Вернемся теперь к самому первому абзацу – триггеры автоматически отслеживают изменение количества элементов у узла дерева. Это означает, что как при создании так при удалении выдается update, в котором обновляется конкретный элемент дерева, причем не тот, который создается или удаляется. Поскольку речь идет о родительском элементе, высока вероятность, что два или более пользователей попытаются одновременно создать дочерние элементы для одного и того же родителя. Это безусловно может привести к конфликтам блокировки, даже если процесс создания (перемещения, удаления) оформить в максимально короткой транзакции.
Что делать? Контролировать блокировки программно – пытаться повторить операцию в случае ошибки (deadlock, а не иной другой) или использовать режим транзакций wait (и тоже повторять неуспешную операцию).
Разграничение доступа
Самый больной вопрос в РСУБД, потому что стандарт не предусматривает разделение доступа к конкретным записям. Права можно дать на выборку из таблицы, ее обновление и т. п., но не на операции с записью. Знатоки Oracle или Linter могут меня поправить – в этих СУБД используется схема разграничения доступа к записям (мандатная защита), однако это реализация требований к защите информации для сертификации, и реально такая схема может иметь массу недостатков для применения в большинстве прикладных областей.Примечание. По Oracle см. также статью.
(Позже, или прямо сейчас, можете прочитать статью www.delphiplus.org/articles/ib/only_for_your_eyes/index.html о варианте разграничения доступа для IB/FB).Второй недостаток РСУБД – отсутствие в стандарте понятия "группа пользователей". Конечно, в InterBase/Firebird есть роли (ROLE), но опять же, в соответствии со стандартом пользователь при коннекте не может получить права, выданные ему в двух или более ролях. Он получает только права одной, конкретно указанной при коннекте роли, плюс те права, которые ему были выданы явно (см. документ).
Далее я приведу два примера реализации разграничения прав доступа на уровне записи – схемы ACL и стандартная RWD.
Внимание! Рекомендуется предварительно хотя бы просмотреть раздел "Права доступа".
Группы пользователей и идентификация
В SQL аналогом "группы" может быть только "роль". Но, как говорилось выше, права разных ролей не "складываются" между собой. В большинстве задач, наоборот, надо чтобы человек мог входить в несколько групп, и автоматически получать права, данные всем этим группам сразу.Раз таких групп, которые нам нужны, в SQL нет, придется отказываться от стандартной системы авторизации. Делается это следующим образом – создается пользователь системы, не SYSDBA, которому выдаются все нужные права для работы с системой. Далее, в базе данных создаются три таблицы: USERS, GROUPS, и USER_GROUPS.
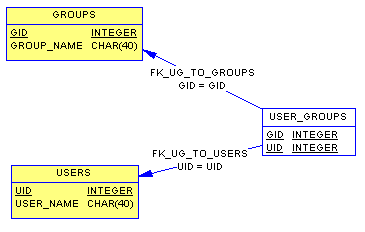
Примечание. Модели выполнены в PowerDesigner 9.5 с использованием шаблона (использовать необязательно) intrbas6d3.xdb (поместите его в подкаталог DBMS установки PD9.5, перед тем как открывать модели, приведенные далее в качестве примеров).
Соответственно, USERS хранит информацию (любую) о пользователях, GROUPS – это справочник групп, существующих в системе, а USER_GROUPS хранит информацию, какой пользователь включен в какую группу.
Проверка прав по маске
Удобнее всего права доступа хранить в одном поле в виде битов, установленных в 0 или 1. При этом потребуется подключение стандартных (или своих) функций логического AND.При этом проверка конкретного бита будет выглядеть как условие (вместо L_AND можно использовать UDF из любого набора, в том числе ib_udf, функция должна выполнять операцию логического AND)
L_AND(FIELD, флаг) <> 0
где "флаг" – число, соответствующее выставленному биту. Например, 4, если выставлен бит 3. При этом можно проверять наличие сразу нескольких прав одновременно, указывая соответствующее значение "флага". Но как правило, в этом нет необходимости, поскольку операции обычно выполняются поодиночке.
Набор прав
Зависит от конкретной прикладной области. Где то хватит стандартных Read, Modify, Delete, где-то будет нужно еще право Create и т. п. И тут есть интересный момент.В обычных файловых системах, для того, чтобы получить доступ к файлу, нужно сначала обратиться в каталог. Если есть право чтения каталога, то выдается список файлов, даже в том случае, если нет права на чтение самих файлов! А ведь имя файла, и особенно имя объекта (или документа) может сказать пользователю очень многое. Представтье себе внутрифирменный документ, который виден всем, но читать его может только администрация, с названием "Убытки за 2-ой квартал"?
Поэтому имеет смысл под правом "чтение" понимать не только право открытия объекта для просмотра его содержимого, но и право видеть его как объект вообще. В конкретной системе, в которой была реализована подобная схема, потребовалось чтобы пользователь мог иметь право создавать объекты в "каталогах", не видя их содержимого. Поэтому право Create имело номер меньший, чем право Read (см. далее раздел RWD). Для примера привожу список констант-прав доступа.
0 none
1 Create
2 Read
4 Modify
8 Delete
16 Move
32 Copy
64 Create shortcut
128 Change access righs
256 Change owner
512 Login
1024 Add to group
2048 Delete from group
4096 Change group
8192 External event
16384 Create group
2768 Modify group
1 Create
2 Read
4 Modify
8 Delete
16 Move
32 Copy
64 Create shortcut
128 Change access righs
256 Change owner
512 Login
1024 Add to group
2048 Delete from group
4096 Change group
8192 External event
16384 Create group
2768 Modify group
Как видно из списка, если потребуется более расширенный набор прав доступа, то битов в поле типа smallint может не хватить. Используйте INTEGER.
ACL
Это Access Control List, т. е. список элементов контроля доступа. Раз у нас есть пользователи, группы и объекты, то с каждым объектом должен быть связан список прав доступа для группы и пользователя. Эта схема используется во многих операционных системах, но чаще всего ее видно в Windows.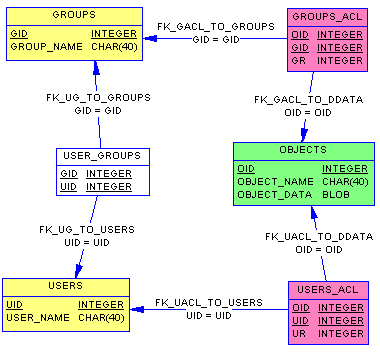
Таблица OBJECTS содержит объекты. USERS_ACL – список прав доступа к объекту для пользователей. GROUPS_ACL – список прав доступа к объекту для групп.
Исходя из схемы видно, что проверить права пользователя на доступ к объекту можно так:
- Выбрать список групп, в которые включен пользователь
SELECT GID FROM USER_GROUPS WHERE UID = :user
- Выбрать права из USERS_ACL
SELECT UR FROM USERS_ACL
WHERE UID = :user AND OID = :object
WHERE UID = :user AND OID = :object
- Выбрать права из GROUPS_ACL (объединяем с выборкой пункта 1)
SELECT GR FROM GROUPS_ACL GA, USER_GROUPS UG
WHERE UG.GID = GA.GID AND UG.UID = :user AND GA.OID = :object
WHERE UG.GID = GA.GID AND UG.UID = :user AND GA.OID = :object
- Объединить права доступа UR и GR, полученные пунктами 2 и 3.
Замечание. Сразу скажу, что GR и UR я изначально принял как битовые маски для прав доступа. А теперь представьте себе, как усложнится приведенная выше схема, если использовать не битовые маски, а отдельные записи со значениями конкретных прав! (Кто готов поспорить, пусть пришлет мне модель и пример запросов на email).
В лучшем случае общая выборка прав даст ни одной или одну запись (с правами либо группы, либо пользователя). Но если пользователь включен в группу, и ему и группе даны права на объект, то получится две записи с OID и правами для группы и пользователя. Может получиться и больше, если пользователь включен в другие группы, а тем в свою очередь выданы права на объект.Поскольку прав доступа может не быть объявлено для группы или пользователя, мы вынуждены использовать outer join для объединения запросов. Итоговый запрос будет выглядеть следующим образом:
SELECT O.OID, O.OBJECT_NAME, O.OBJECT_DATA, GA.GR, UA.UR
FROM
USER_GROUPS UG
JOIN
GROUPS_ACL GA
ON UG.GID = GA.GID AND UG.UID = :user
RIGHT JOIN OBJECTS O
ON GA.OID = O.OID
LEFT JOIN USERS_ACL UA
ON UA.OID = O.OID AND UA.UID = :user
FROM
USER_GROUPS UG
JOIN
GROUPS_ACL GA
ON UG.GID = GA.GID AND UG.UID = :user
RIGHT JOIN OBJECTS O
ON GA.OID = O.OID
LEFT JOIN USERS_ACL UA
ON UA.OID = O.OID AND UA.UID = :user
Запрос будет выбирать все объекты, на которые пользователь user имеет любые права. Если нужно выбрать конкретный объект и его права, то к запросу следует добавить WHERE O.OID = :object.
Для примера приведу результат такой выборки (для всех записей):
OID OBJECT_NAME OBJECT_DATA GR UR
1 Object1 modify modify
1 Object1 read modify
2 Object2 null null
3 Object3 modify null
1 Object1 modify modify
1 Object1 read modify
2 Object2 null null
3 Object3 modify null
Представим себе, что есть пользователи 1 и 2, группы 1 и 2. Пользователь 1 включен в группы 1 и 2, пользователь 2 – только в группу 1. На объект 1 даны права пользователю 1 (изменение), группе 1 (изменение), группе 2 (чтение). На объект 3 даны права пользователю 2 на изменение. Первая запись в списке содержит права группы 1 и пользователя 1. Вторая запись в списке содержит права группы 2 и пользователя 1.
Чем больше будет дано прав на объект 1, тем больше записей с этим идентификатором может появиться. Мы не можем использовать distinct для "схлопывания" повторяющихся идентификаторов, т.к. права пользователя и группы могут быть разные, могут иметь разный приоритет, и в любом случае должны быть "просуммированы". Например, пользователь 1 включен в группы 1 и 2, которые имеют право изменения и чтения, соответственно. Максимальным правом получается "изменение". Типов прав может быть много, если это не битовая маска, то допустимо выполнение агрегатной операции SUM(GR) (если битовая маска, то сложение бита 4 и 4 приведет к результату равному 8. А в случае битовых масок сложение должно быть по логическому OR. Такой агрегатной функции, к сожалению, нет). Однако у нас и так запрос имеет план не очень красивый, а если еще добавить агрегаты, то скорость выполнения такого запроса будет весьма низкой. Кроме того, как правило, на один объект накладывают несколько прав доступа. Если даже в среднем один объект будет иметь 4-5 прав доступа, то это означает, что в таблицах X_ACL в сумме будет записей в 4-5 раз больше, чем в таблице объектов.
В общем, схему ACL можно считать для РСУБД неподходящей. Кроме того, ее весьма сложно администрировать.
Примечание. Может возникнуть вопрос – если эта схема такая неудобная, то почему она нормально работает в файловых системах? В файловых системах не возникает таких запросов (и так часто), как в РСУБД. Поэтому затраты на "сборку" прав доступа для объекта можно считать несущественными.
Файл: acl.pdm для PowerDesigner 9.5
RWD
Стандартная схема предполагает хранение прав доступа в привязке к конкретному объекту, причем всего в трех полях – права пользователя (UR), права группы (GR), права всех (AR). Т.е. в этом случае достаточно изменить структуру таблицы объектов следующим образом:ALTER TABLE OBJECTS
ADD UID INT NOT NULL REFERENCES USERS,
ADD UR INT DEFAULT 255,
ADD GID INT NOT NULL REFERENCES GROUPS,
ADD GR INT DEFAULT 255,
ADD AR INT DEFAULT 0
ADD UID INT NOT NULL REFERENCES USERS,
ADD UR INT DEFAULT 255,
ADD GID INT NOT NULL REFERENCES GROUPS,
ADD GR INT DEFAULT 255,
ADD AR INT DEFAULT 0
В данном случае default указаны как битовые маски, включающие в себя все права по умолчанию для создателя документа и его группы. References для лучшей читаемости структуры БД лучше заменить на явно создаваемый constraint xxx foreign key (здесь references приведено только для наглядности).
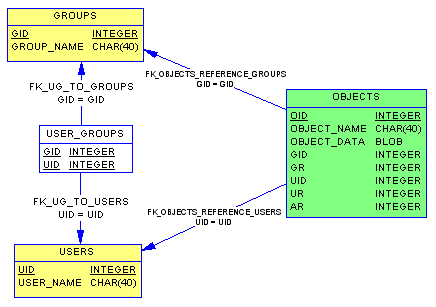
Т. е. при выборке объектов мы сразу получаем информацию о "владельце" объекта и его правах (UID и UR), группе объекта и ее правах (GID и GR), и правах для всех (AR).
Такая схема позволяет практически мгновенно при выборе объекта определить, имеет пользователь права соответствующего доступа к этому объекту, или нет. Выражаясь более простым языком – такая проверка очень легко помещается в конструкцию where.
Единственной проблемой может казаться здесь проверка присутствия пользователя в конкретной группе, если нет доступа для всех и пользователь не является "владельцем" объекта. Однако это тоже легко решается вложенным подзапросом. Итак, при выборке мы проверяем следующие условия:
(права_всех) OR
((пользователь = владелец) AND (права_пользователя)) OR
((группа_пользователя = группа) AND (права группы))
((пользователь = владелец) AND (права_пользователя)) OR
((группа_пользователя = группа) AND (права группы))
Данная схема не совсем соответствует проверке прав на Unix – там если идентификатор пользователя (владельца) совпадает, то проверка дальше не производится. В IB используется проверка всех условий OR во время выполнения оператора, так что если пользователь – владелец записи, то права группы все равно будут проверяться.
При проверке прав есть два случая – проверка прав при чтении, и проверка прав вообще. При чтении нет необходимости проверять остальные права. Они, соответственно, должны проверяться только при других операциях – изменении, копировании и т. п.
При чтении объектов:
SELECT O.OID, O.OBJECT_NAME, O.OBJECT_DATA
FROM OBJECTS O
WHERE
(O.OWNER_ID = :OID) AND
((O.AR >= 2) OR
((O.UID = :UID) AND (O.UR >= 2)) OR
((O.GR >= 2) AND
(O.GID IN
(SELECT UG.GID FROM USER_GROUPS UG
WHERE
(UG.UID = :UID)))))
FROM OBJECTS O
WHERE
(O.OWNER_ID = :OID) AND
((O.AR >= 2) OR
((O.UID = :UID) AND (O.UR >= 2)) OR
((O.GR >= 2) AND
(O.GID IN
(SELECT UG.GID FROM USER_GROUPS UG
WHERE
(UG.UID = :UID)))))
Если не нравится конструкция IN, то ее можно заменить на
(EXISTS
(SELECT UG.GID FROM USER_GROUPS UG
WHERE
(UG.UID = :UID)))))
(SELECT UG.GID FROM USER_GROUPS UG
WHERE
(UG.UID = :UID)))))
При этом скорость выборки является максимально возможной, и нет никаких проблем, существующих в модели ACL.
При проверке прав "вообще" можно использовать процедуру вида (входные параметры – пользователь, группа, идентификатор объекта, действие (право)):
CREATE PROCEDURE CHECKRIGHTS(
UID INT, GID INT, OID INTEGER, ACT INTEGER)
RETURNS (CANDO INTEGER)
AS
DECLARE VARIABLE UI INTEGER;
DECLARE VARIABLE GI INTEGER;
DECLARE VARIABLE URR INTEGER;
DECLARE VARIABLE GRR INTEGER;
DECLARE VARIABLE ARR INTEGER;
DECLARE VARIABLE RC INTEGER;
BEGIN
CANDO=0; UI=NULL; GI=NULL; URR=NULL; GRR=NULL; ARR=NULL;
SELECT O.UID, O.GID, O.UR, O.GR, O.AR
FROM OBJECTS O
WHERE O.OID=:OID
INTO :UI, :GI, :URR, :GRR, :ARR;
/* no such document - do what you want */
if ((:UI IS NULL) or (:GI IS NULL)) then
begin
CANDO=1;
SUSPEND;
end
/* check rights: all, user's, group's */
if ((L_AND(:ARR, :ACT) <> 0) or
((:UID = :UI) and (LAND(:URR, :ACT) <> 0)) or
((:GID = :GI) and (LAND(:GRR, :ACT) <> 0))) then
CANDO=1;
else
/* check if user in any group that have same gid */
if (:GID <> :GI) then
begin
rc=0;
select count(*) from user_groups ug
where (ug.uid = :UID) and (ug.gid = :GI)
into :RC;
if ((:RC <> 0) and (L_AND(:GRR, :ACT) <> 0)) then
CANDO=1;
end
SUSPEND;
END
UID INT, GID INT, OID INTEGER, ACT INTEGER)
RETURNS (CANDO INTEGER)
AS
DECLARE VARIABLE UI INTEGER;
DECLARE VARIABLE GI INTEGER;
DECLARE VARIABLE URR INTEGER;
DECLARE VARIABLE GRR INTEGER;
DECLARE VARIABLE ARR INTEGER;
DECLARE VARIABLE RC INTEGER;
BEGIN
CANDO=0; UI=NULL; GI=NULL; URR=NULL; GRR=NULL; ARR=NULL;
SELECT O.UID, O.GID, O.UR, O.GR, O.AR
FROM OBJECTS O
WHERE O.OID=:OID
INTO :UI, :GI, :URR, :GRR, :ARR;
/* no such document - do what you want */
if ((:UI IS NULL) or (:GI IS NULL)) then
begin
CANDO=1;
SUSPEND;
end
/* check rights: all, user's, group's */
if ((L_AND(:ARR, :ACT) <> 0) or
((:UID = :UI) and (LAND(:URR, :ACT) <> 0)) or
((:GID = :GI) and (LAND(:GRR, :ACT) <> 0))) then
CANDO=1;
else
/* check if user in any group that have same gid */
if (:GID <> :GI) then
begin
rc=0;
select count(*) from user_groups ug
where (ug.uid = :UID) and (ug.gid = :GI)
into :RC;
if ((:RC <> 0) and (L_AND(:GRR, :ACT) <> 0)) then
CANDO=1;
end
SUSPEND;
END
Здесь сначала проверяются права пользователя и его группы, а если прав нет, проверяются права для всех остальных групп, в которые включен пользователь.
Файл: rwd.pdm для PowerDesigner 9.5
Иерархия групп
Интересно, что в предложенной реализации совершенно не имеет значения, каким образом устроен список групп – линейно или иерархически. Фокус в том, что все равно у конкретной записи есть только один идентификатор группы, к которой она принадлежит. Поэтому задача системы контроля прав – проверить, участвует ли пользователь в этой группе или нет. Значит, иерархия групп имеет смысл только для визуального отображения взаимозависимостей групп, и в частности облегчает управление пользователями (включение их в группы).Вот два примера иерархии:
1. права снизу вверх
разработчики
ПроектА
ПроектБ
ПроектБ
В этом случае есть группа "Разработчики", в которую включены все разработчики компании. Документы для группы "Разработчики" могут быть самыми разнообразными – конференции, примеры кода, правила оформления исходных текстов и т. п. Т. е. все разработчики компании должны иметь к ним доступ. Однако на уровне конкретных проектов в группы включаются только те разработчики, которые непосредственно участвуют в этих проектах. Например, Иванов М. Е. – разработчик, включен в группу "Разработчики" и "ПроектА". В этом случае он не может работать с записями, принадлежащими группе "ПроектБ".
2. права сверху вниз
администрация
бухгалтерия
плановый отдел
плановый отдел
В этом случае директор Сидоров П.А., входящий в группу "администрация", должен автоматически быть включен в группы "плановый отдел" и "бухгалтерия". Наоборот, бухгалтер Иванова М. И. не должна быть включена в группу "администрация".
Собственно, еще раз подчеркну, что иерархия нужна только для визуального отображения. Можно сделать программу управления группами так, что добавляя Иванову М. И. в группу "Бухгалтерия" программа нам будет предлагать – или автоматически включить Иванову во все вышестоящие группы, или автоматически включить Иванову во все нижестоящие группы. Таким образом, список групп остается линейным, что ускоряет проверки доступа и позволяет визуально выстраивать любые иерархии групп.
Реализация дерева групп
Напрасно надеетесь увидеть здесь конкретный пример. Дерево групп организуется тем же самым способом, что и обычное "дерево", о котором рассказано в первой части статьи. Более того, в случае реально работавшей системы, древовидное отображение групп было добавлено намного позже (изначально группы были линейными, просто у таблицы и так был столбец id, а добавление столбца parent_id просто позволило выстраивать группы древовидно), что никак не отразилось на остальной части БД (были дописаны процедуры и триггеры для обработки USER_GROUPS).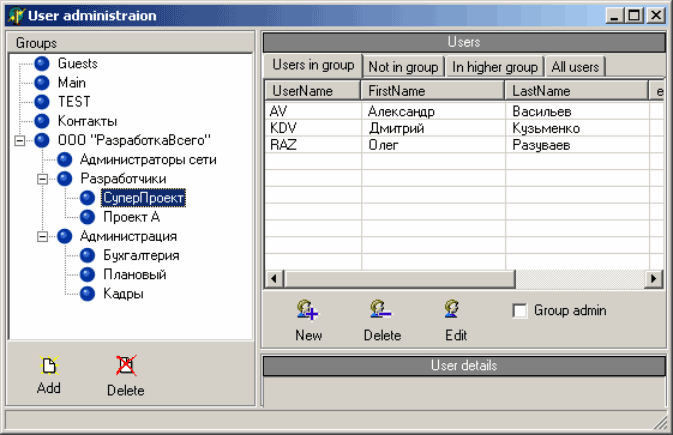
Администрирование прав RWD
Несмотря на кажущуюся простоту схемы прав RWD мне не удалось найти в сети ни одного документа, который бы описывал пример процедуры настройки прав (создание групп пользователей, разделение прав и т. п.) (Если видели пришлите ссылку).Давайте попробуем оценить сложность администрирования такой схемы на примере.
Когда пользователь создает объект, то он автоматически становится его владельцем, т.е. может делать с этим объектом все что угодно. Если в этот же момент выдаются права на доступ всем (столбец AR, упомянутый в предыдущих разделах), то эти права проверяются для всех, независимо от нахождения в группах.
Единственным правом доступа, которое позволяет ограничить общение с объектом для конкретной группы пользователей, является идентификатор группы объекта. Поэтому дальше мы будем говорить именно о правах группы, а не оправах "всех" или правах пользователя на объект.
Таким образом, если пользователь А создает объект (документ), и хочет чтобы пользователи B и C также имели к нему доступ, мы должны создать группу X, включить туда пользователей A, B и C, и при создании объекта указать в GroupId идентификатор группы X, а в правах группы указать как минимум право на чтение.
Теперь, если появляется новый пользователь, который должен получить доступ к объекту, мы должны его включить в группу X.
Однако, при этом такой пользователь получит доступ ко всем объектам (документам_, созданным с GroupId = X. А если нужно дать доступ только к одному или нескольким конкретным объектам?
В этом случае придется сделать следующее:
- создать новую группу, например Z
- включить в группу Z тех, кто публикует объект (документ)
- включить в группу Z тех, кто должен получить доступ к объекту
Например, существует две группы разработчиков. На определенном этапе им понадобилось обмениваться между собой определенными документами. Чтобы не давать доступ ко всем документам той или иной группы, создается новая группа, куда включаются все, кто должен получить доступ к публикуемым таким образом документам.
Причем если документ уже существует как документ одной из этих групп, придется или сменить его GroupId на новый, или же, если нельзя "вытаскивать" документ из группы, нужно создать копию документа, у которой права на доступ будут правами не исходной группы, а правами общей, созданной для обмена документами.
Соответственно выглядеть это может как
- Каталог группы А
- документ 1
- документ 2
- Каталог группы Б
- документ 3
- документ 4
- Общий каталог группы Z
- копия (или ссылка) документа 1
- копия (или ссылка) документа 3
Здесь есть потенциальная дыра в безопасности, особенно если использовать разные права на доступ к самому документу и его ссылке (shortcut). Дело в том, что один документ как таковой (т. е. с одним содержимым) виден разным группам пользователей с разными правами. И на определенном этапе пользователи группы Б могут "забыть", что документ 3 "опубликован" для группы Z. В частности, необходимо не давать возможности для документов, принадлежащих группе Z, изменять права доступа.
Печально, что часто как администраторы, так и пользователи, не желая разбираться даже с примитивными правилами определения прав доступа на каталоги и документы, стараются минимизировать объем своей работы, что приводит к появлению "свалок документов", с последующей утечкой информации и другими неприятными для безопасности эффектами.
Указание прав при создании объекта
Здесь нет четких рекомендаций, нужно только учитывать особенности раздачи прав, указанные в предыдущем разделе. Если права самого пользователя (и "для всех") можно назначить "по умолчанию", то наилучшим вариантом осуществить указание умолчательных прав доступа для группы будет брать такие права непосредственно у каталога, в котором создаются объекты.Исходя из изложенного выше, например, для группы Z устанавливается невозможность смены прав доступа, копирования, и перемещения объектов (по каталогам). Тогда при создании объекта в таком каталоге он автоматически должен получить идентификатор группы, которой принадлежит каталог (группа Z), а также ограничения по правам для этого каталога.
Наследование прав
Продолжение следует... Далее будут: объединение схем RWD и ACL...
Литература
- ООП в РСУБД LINK
- Применение XML для хранения сложных объектов LINK
- Представление объектов в реляционных базах данных, на английском языке
- Комментарий к этой статье "Древовидные ..." LINK
- Письмо по поводу древовидных структур
- Компонент IBX для работы с древовидными структурами по статье
- "Registry" в базе данных LINK
- Моделирование квазиструктурированных данных
- Деревья в SQL, часть 1, Joe Celko, на английском языке
- Деревья в SQL, часть 2, Joe Celko, на английском языке
- Деревья в SQL, часть 3, Joe Celko, на английском языке
- Еще раз про деревья, Joe Celko, на английском языке
- Все три части "Деревья в SQL", на русском языке
- Вариант решения некоторых проблем деревьев
- Компонент для работы с деревьями через IBX
- Применение деревьев в системах бухучета
- Суммирование в деревьях